ICLR 2026 · Poster
Controlling Repetition in Protein Language Models


ICLR 2026 · Poster
Protein language models frequently collapse into long repeats (AAAAAA) and short motif loops (AGAGAG). These sequences do not fold. We quantify this failure, and introduce UCCS — Utility-Controlled Contrastive Steering — a training-free method that reduces repetition while simultaneously raising AlphaFold confidence across ESM-3 and ProtGPT2.
Motif-level and homopolymer collapse in PLMs tracks AlphaFold pLDDT, not just token diversity.
Temperature, top-p, and repetition-penalty either barely move repetition or lower foldability.
UCCS is the only method that improves both repetition and utility on all tested datasets and models.
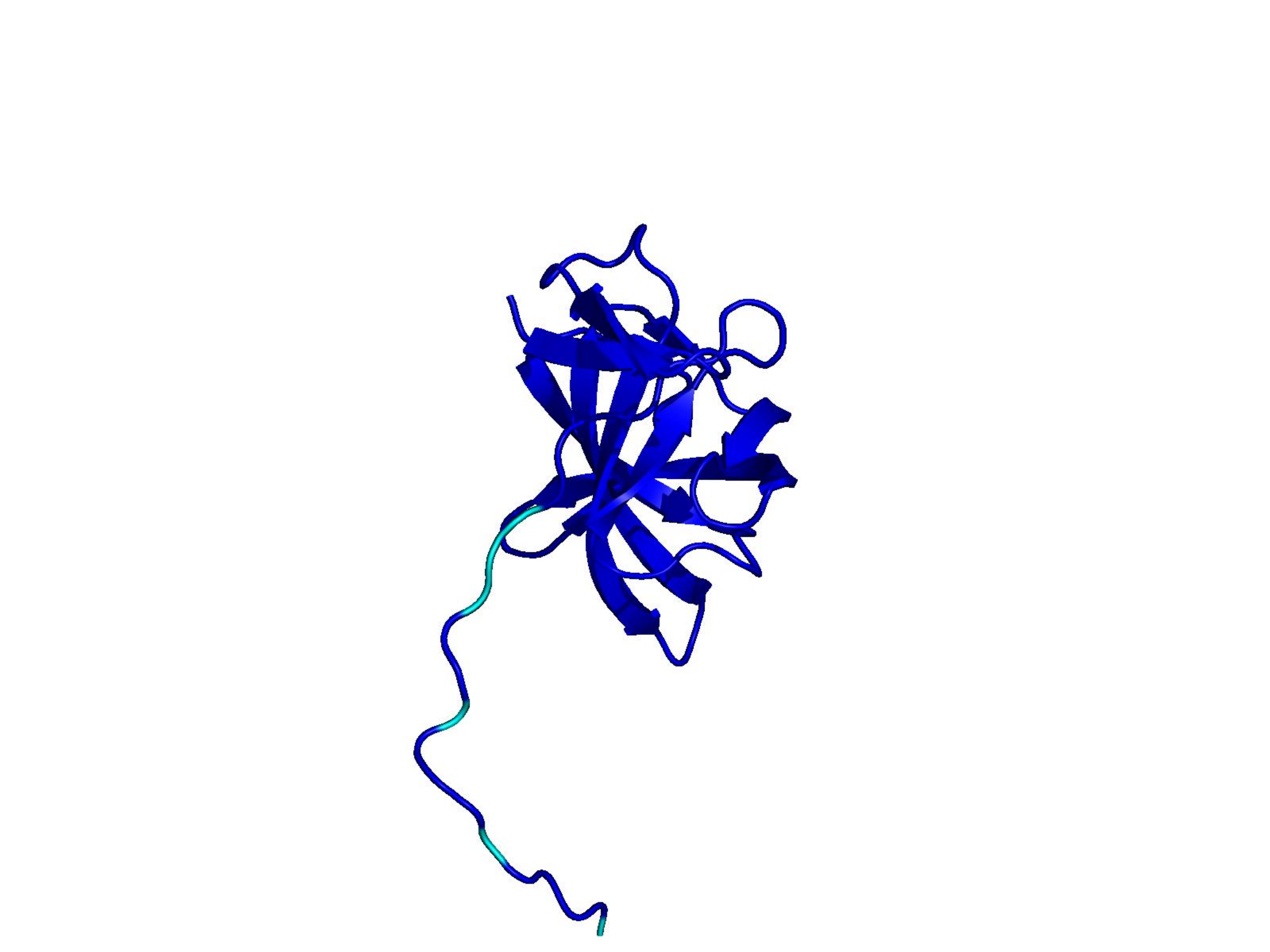
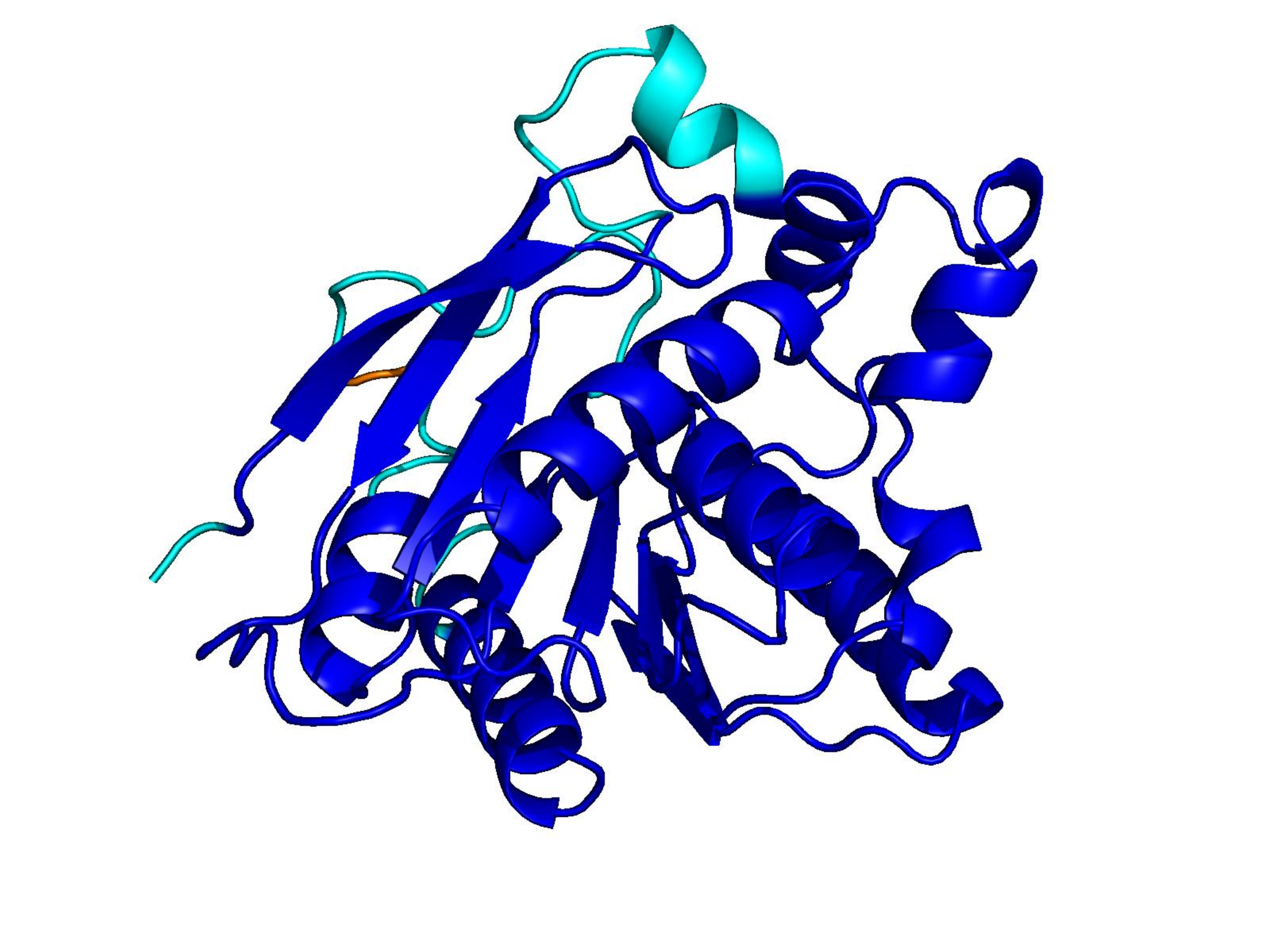
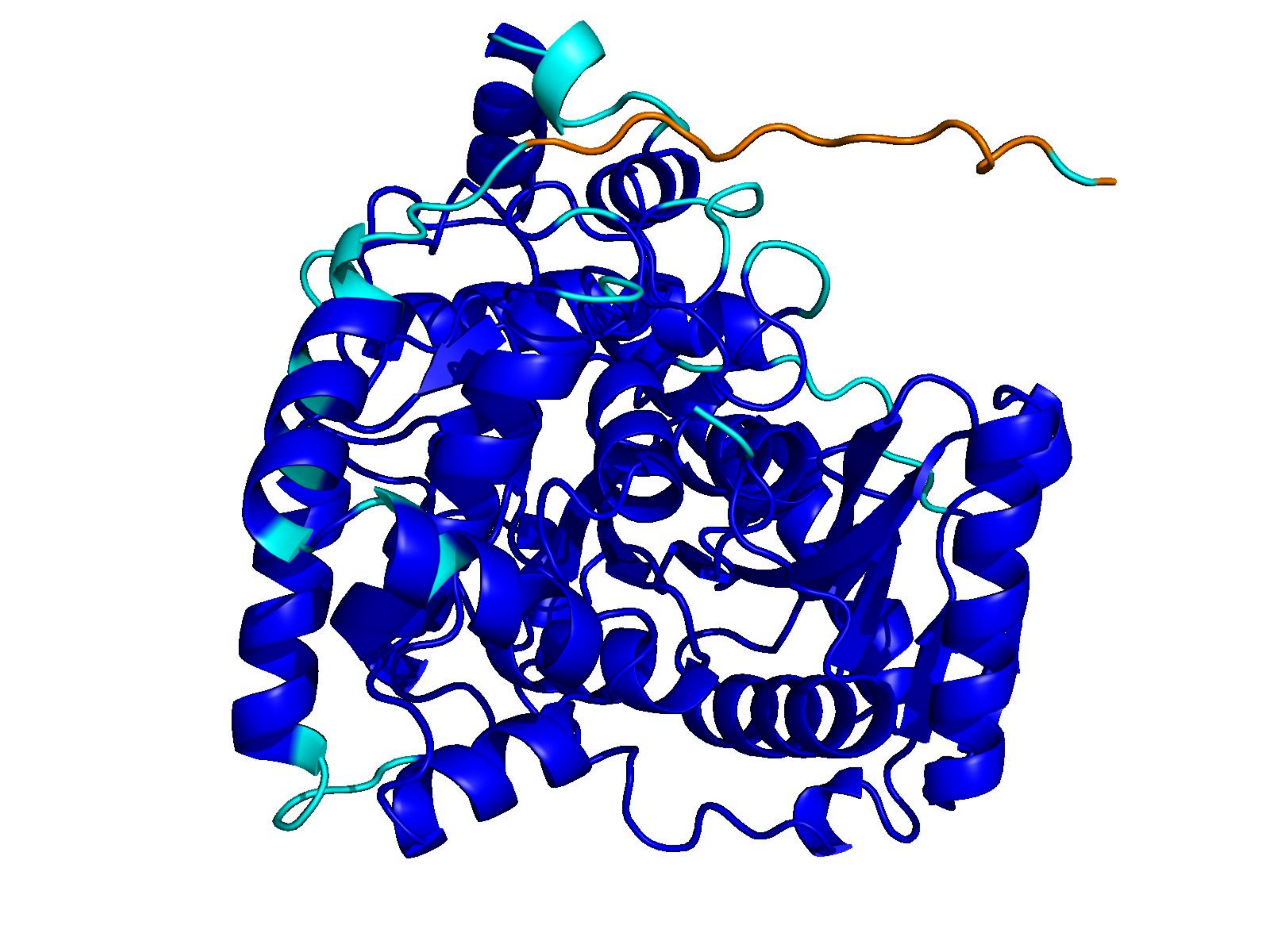
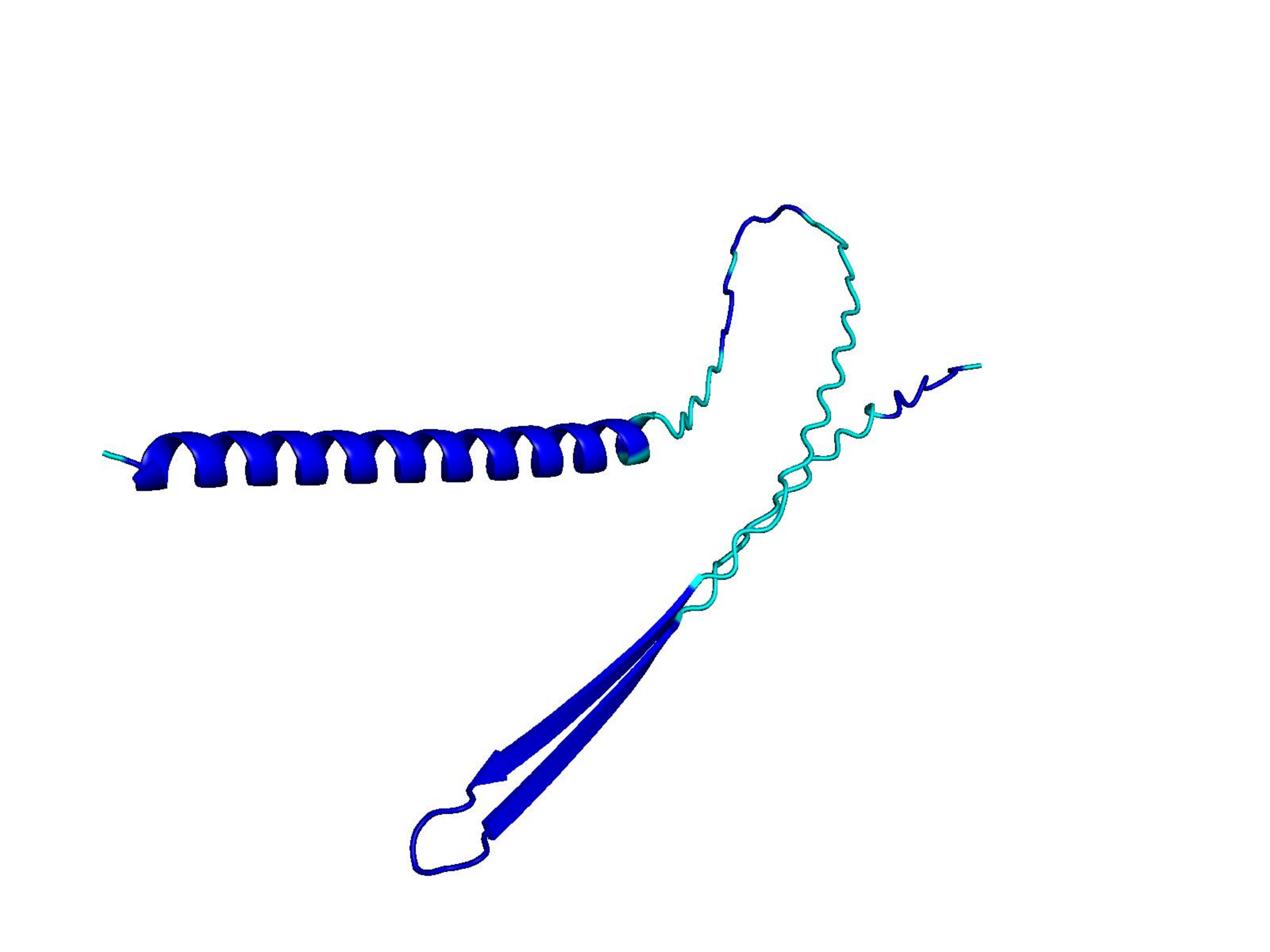
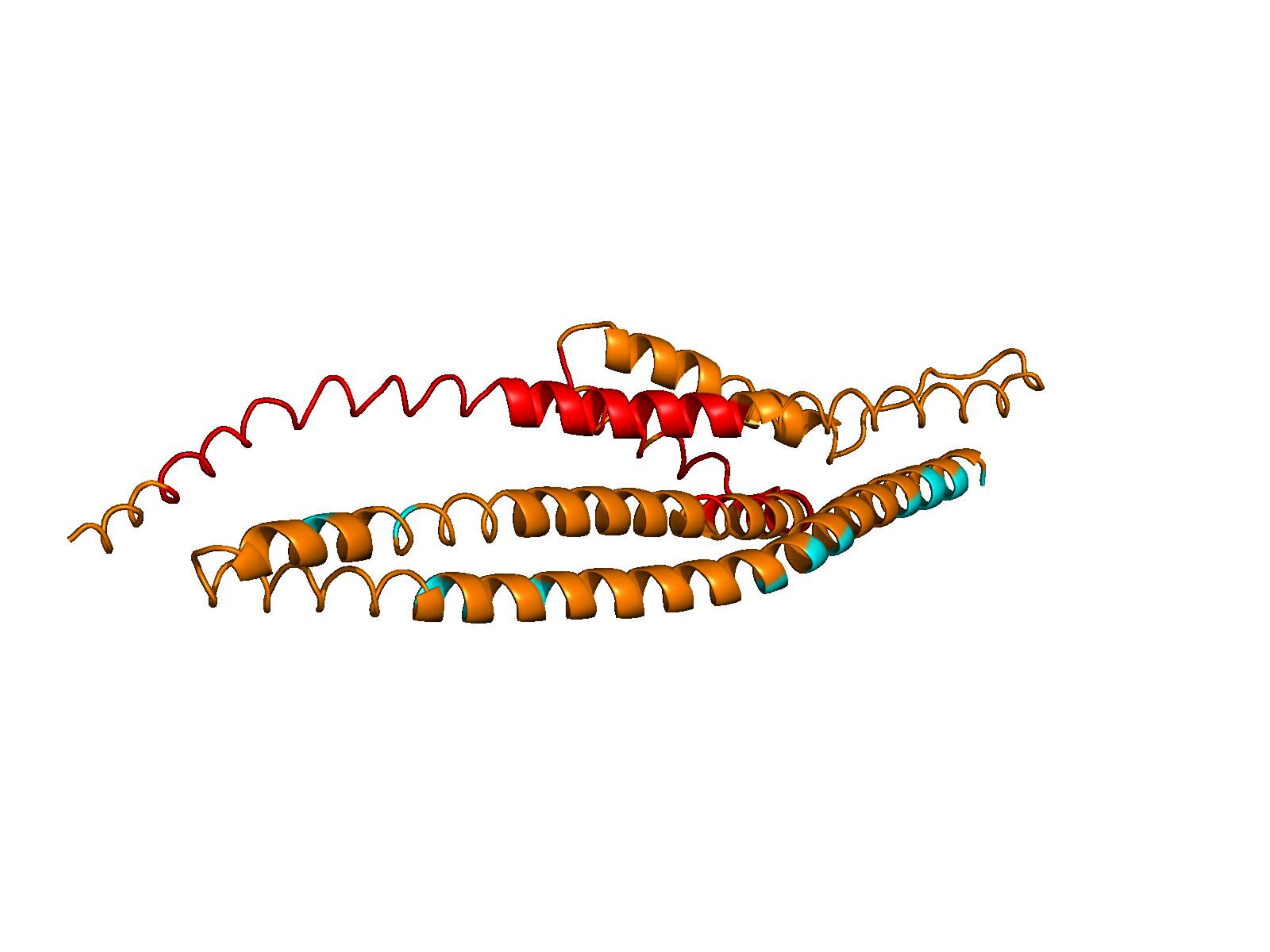
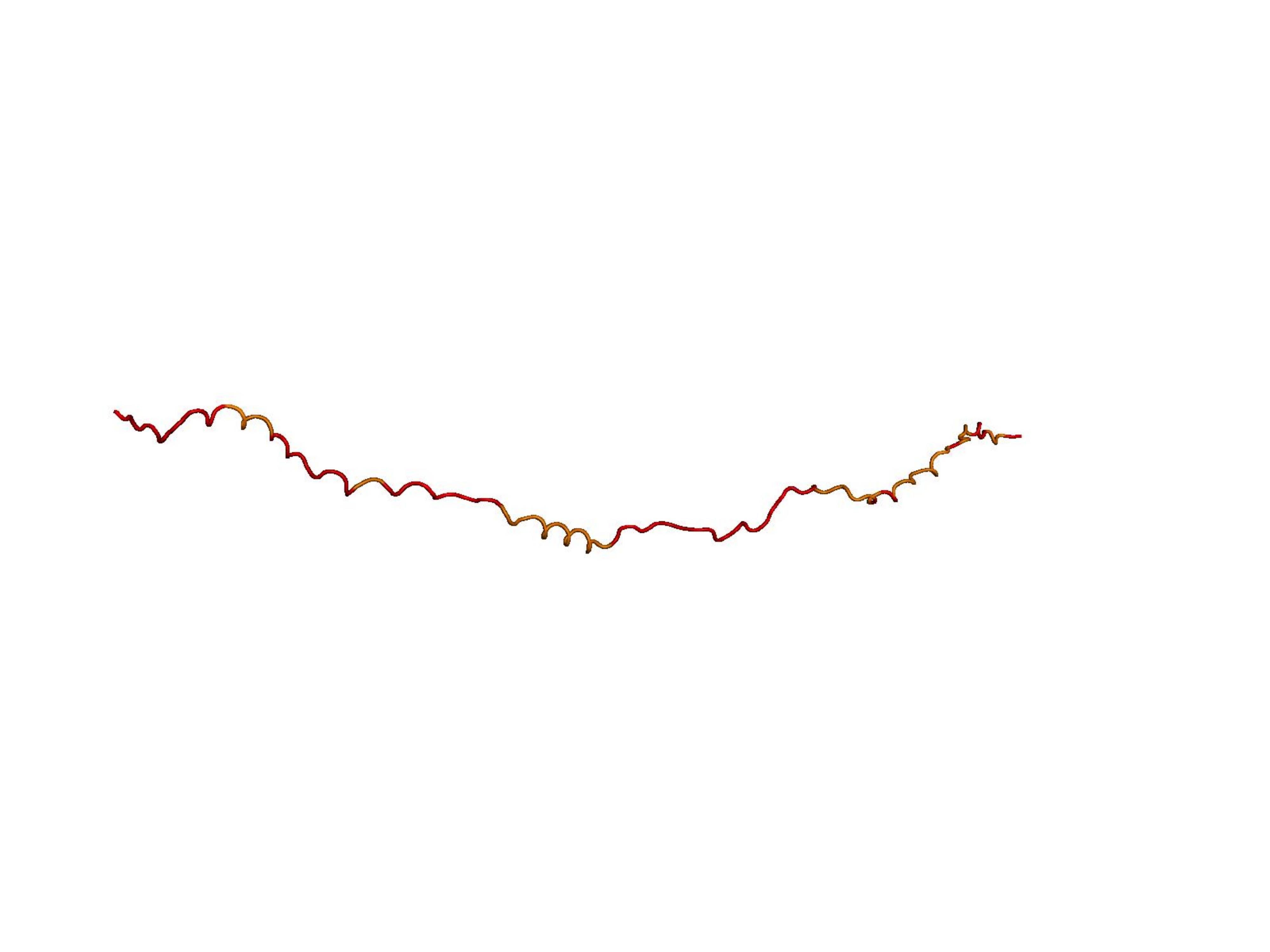
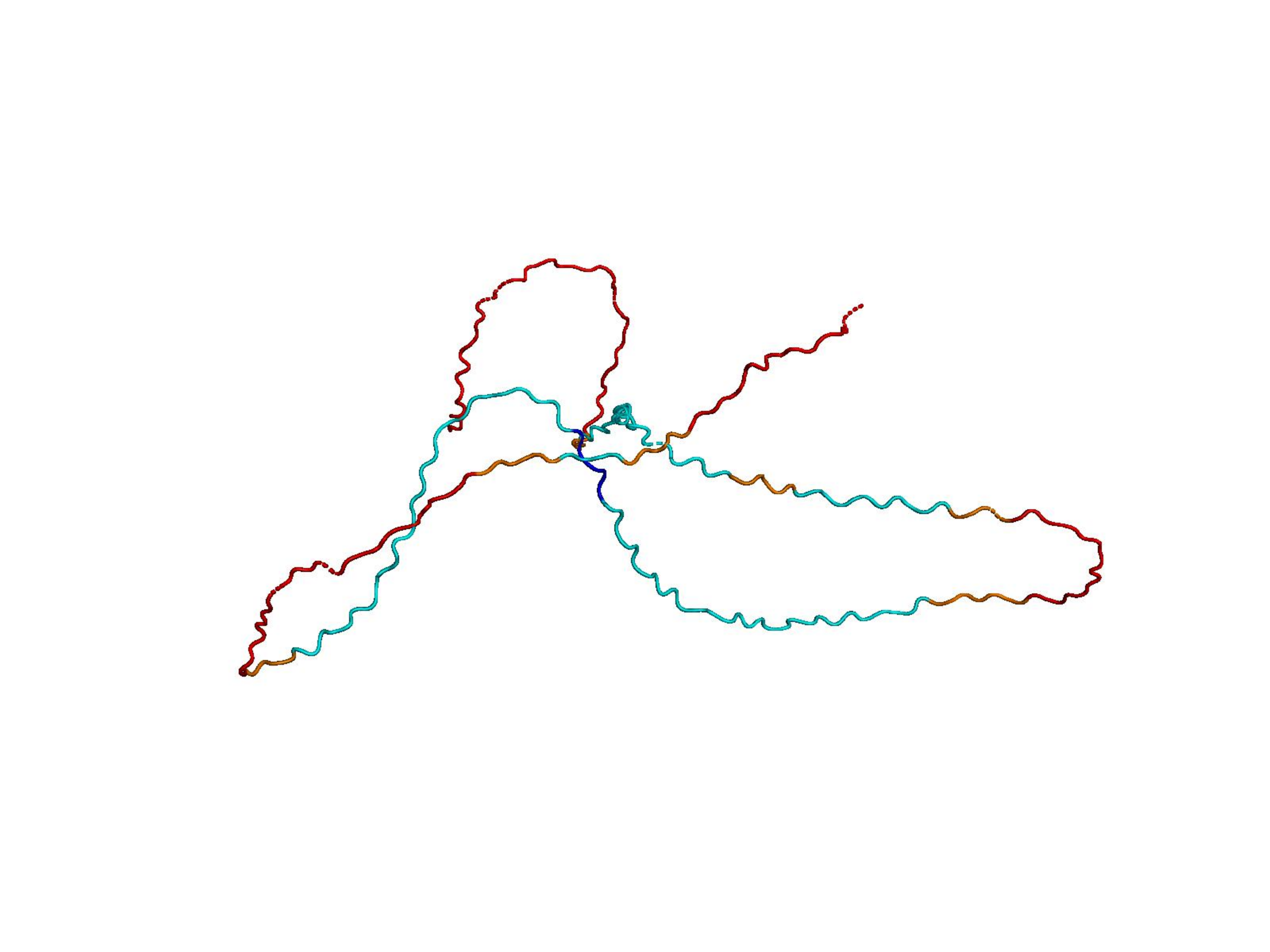
Raw ESM-3 / ProtGPT2 generations often collapse into low-complexity sequences that AlphaFold cannot confidently fold. Natural proteins (top row) vs. unmodified model outputs (bottom rows). Color = per-residue pLDDT (blue ≈ 100, orange/red < 50).


Higher R(x) = less repetitive.
AlphaFold-derived structural confidence:
$U(x) \;=\; \tfrac{1}{2}\bigl(\mathrm{pLDDT}(x) + \mathrm{pTM}(x)\bigr)$
Higher U(x) = more confident fold.
The core obstacle. On real datasets, low-repetition and high-utility are entangled. Naively steering "away from repetition" usually also pushes the model away from foldability — because the direction you learn from raw contrastive data is a mixture of both.
UCCS builds contrastive sets that are matched in utility and separated in repetition, so the mean-difference vector isolates a pure "repetition direction" in hidden space.
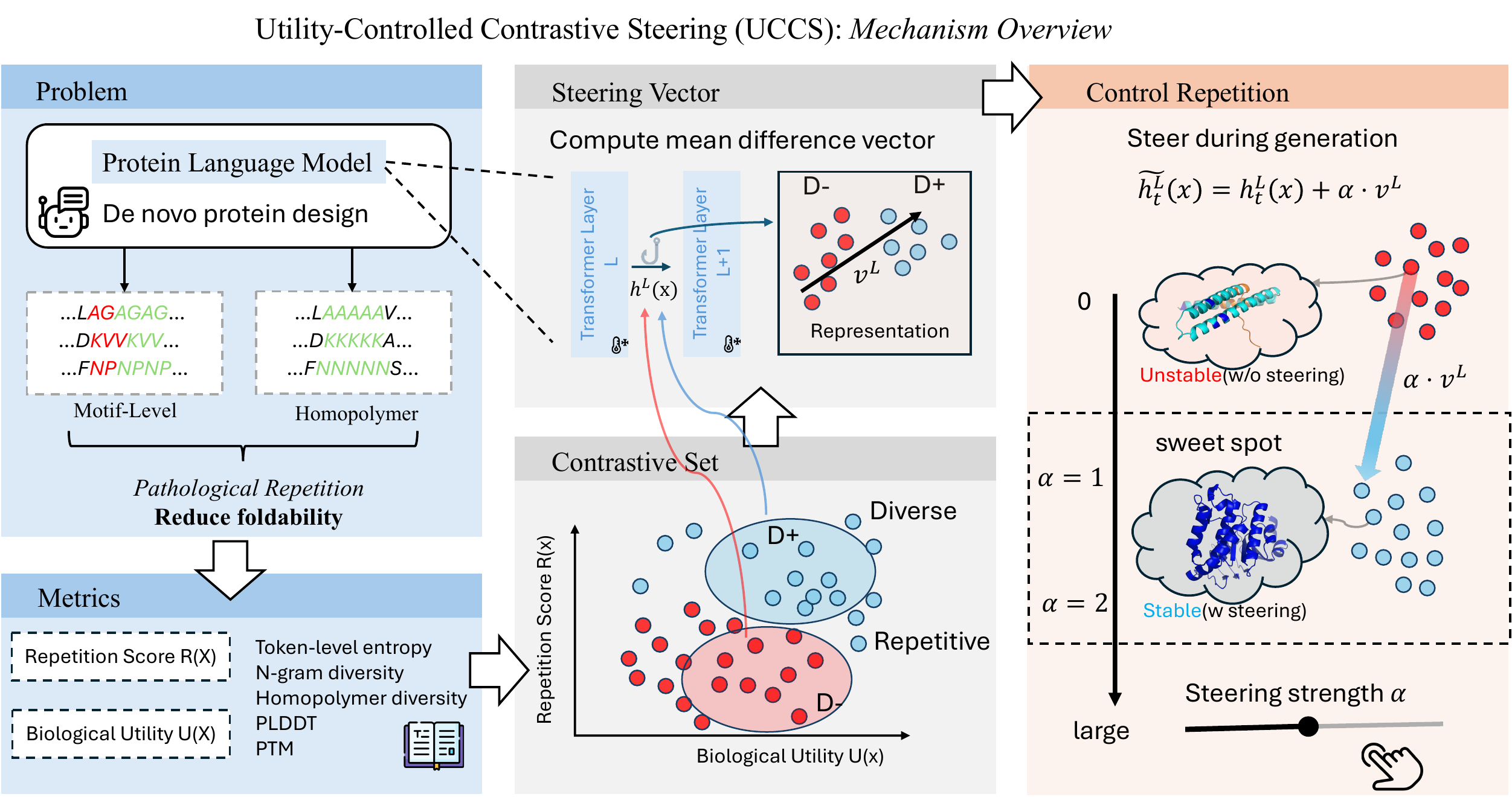
$$\min_{f}\; R\!\left(f(M, p)\right) \quad \text{s.t.}\quad U\!\left(f(M, p)\right) \;\ge\; U(M, p) - \epsilon$$
We do not retrain $M$. Instead we modify its forward pass by adding a fixed direction to hidden activations at a chosen layer.
$$\phi^L(x) \;=\; \begin{cases} \tfrac{1}{T}\sum_{t=1}^T h^L_t(x) & \text{MLM (ESM-3, mean pool)}\\[4pt] h^L_T(x) & \text{AR-LM (ProtGPT2, last token)} \end{cases}$$
MLMs encode bidirectionally, so mean-pool; AR-LMs concentrate predictive information at the last token.
Pareto or composite selection over ~10 k candidates → ~100 matched pairs. Utility matching is what makes the steering direction clean.
Default $\alpha = 1$. Unimodal across $[0.5, 4]$. Larger $\alpha$ emphasises $R$; smaller $\alpha$ protects $U$.
Late layers work best. ESM-3: $L \approx 46/48$. ProtGPT2: $L \approx 30/36$. Early-layer injection is inert or harmful.
Across CATH, UniRef50 and SCOP, on both ESM-3 (MLM) and ProtGPT2 (AR-LM), UCCS is the only method that improves both repetition $R$ and utility $U$ relative to the unmodified baseline.
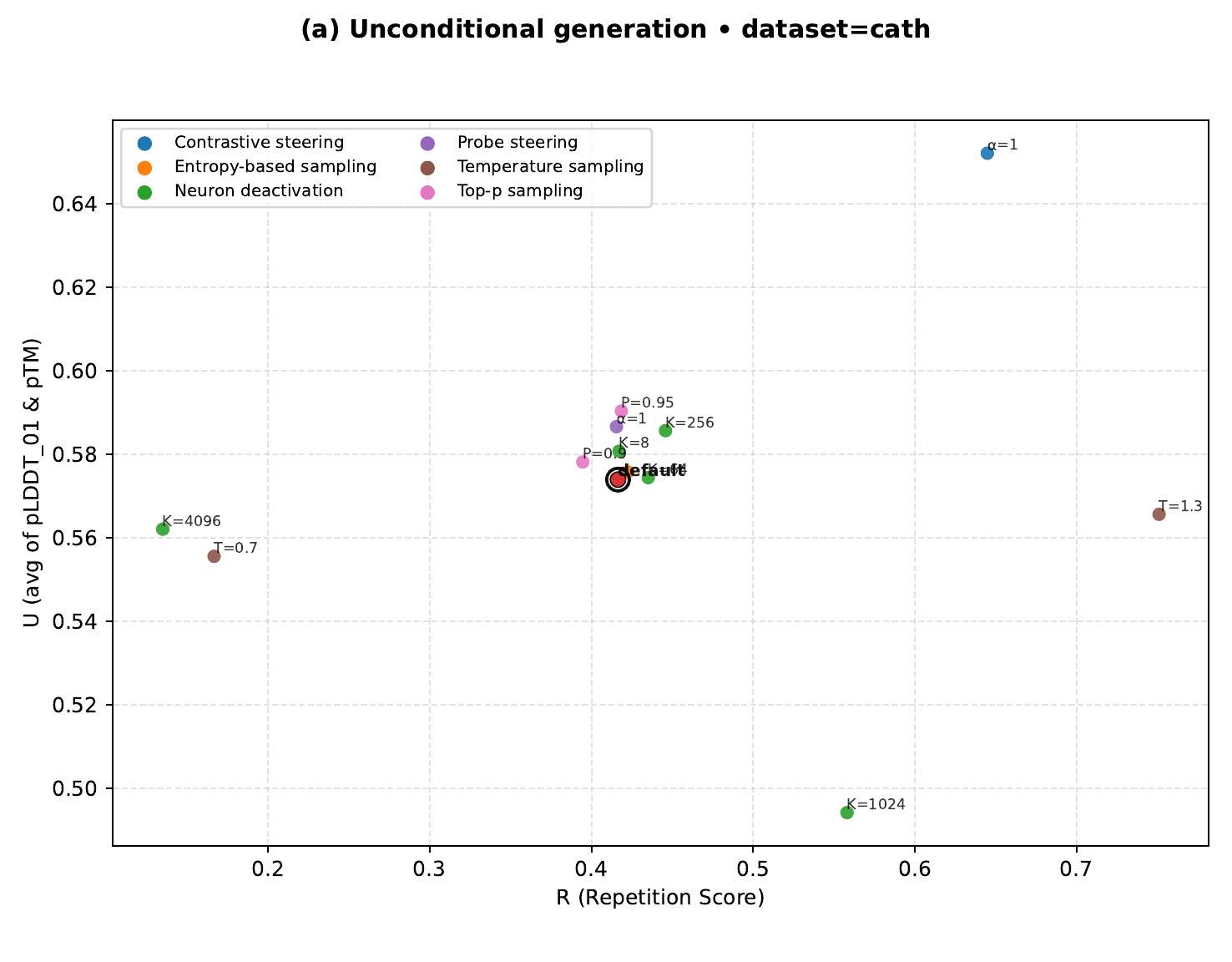
Temperature sampling raises $R$ to 0.751 but drops $U$ to 0.566 — the trade-off UCCS breaks.
| Method | R ↑ | U ↑ |
|---|---|---|
| Original (no intervention) | 0.423 | 0.576 ✓ |
| Temperature sampling | 0.751 | 0.566 |
| Top-p sampling | 0.419 | 0.590 ✓ |
| Entropy-based sampling | 0.904 | 0.477 |
| Neuron deactivation | 0.551 | 0.507 |
| Probe steering | 0.415 | 0.587 ✓ |
| UCCS (ours) | 0.645 | 0.652 ✓ |
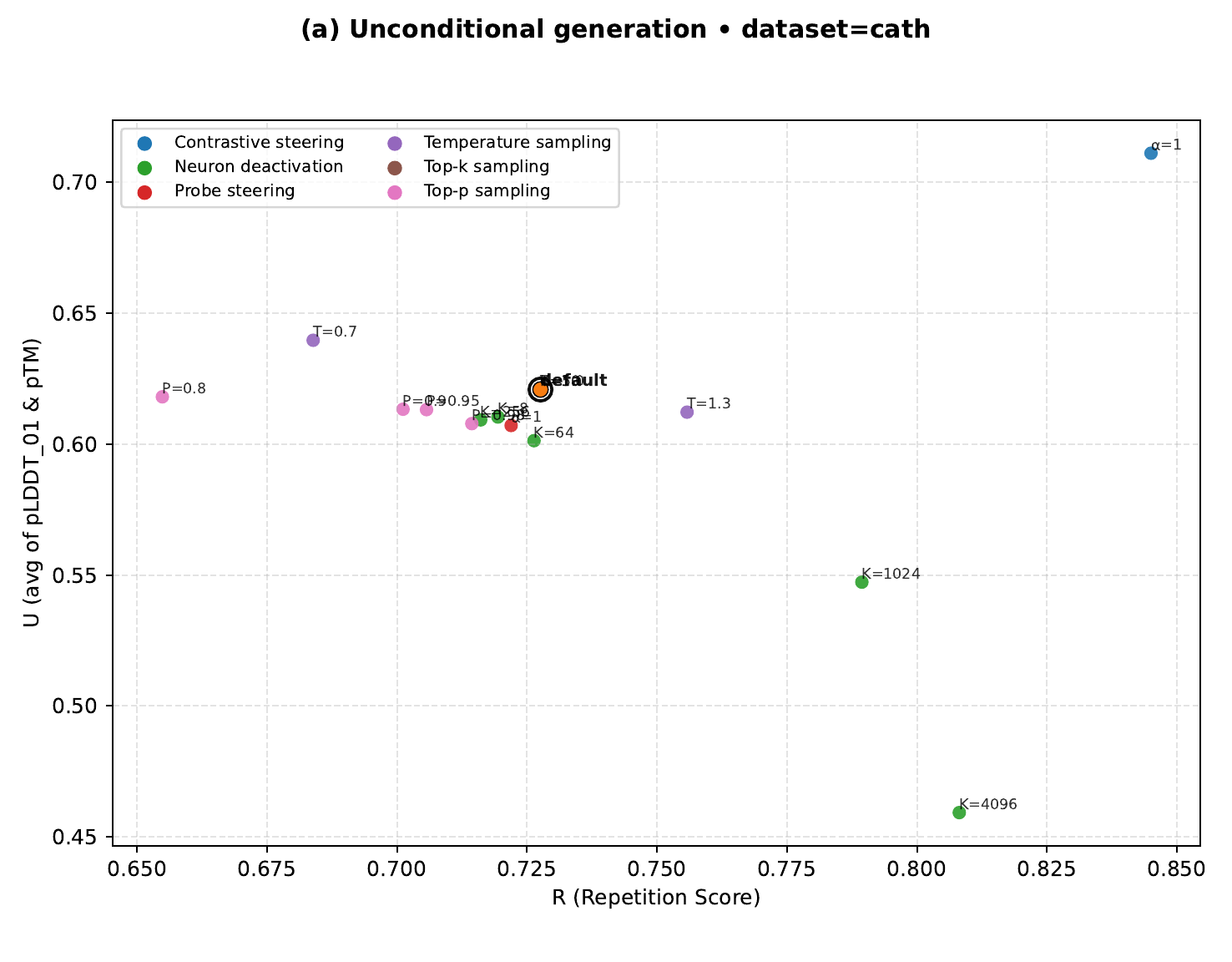
Repetition-penalty and n-gram blocking barely move $R$ and do not help $U$.
| Method | R ↑ | U ↑ |
|---|---|---|
| Original (no intervention) | 0.728 | 0.621 ✓ |
| Temperature sampling | 0.756 | 0.612 |
| Top-p sampling | 0.714 | 0.608 |
| No-repeat n-gram | 0.736 | 0.613 |
| Repetition penalty | 0.780 | 0.622 ✓ |
| Neuron deactivation | 0.719 | 0.610 |
| Probe steering | 0.722 | 0.607 |
| UCCS (ours) | 0.845 | 0.711 ✓ |
Same pattern holds for UniRef50 and SCOP, and for conditional (prefix-10) generation — see the paper's Tables 1 and 2 for all 12 settings.
Pareto and composite selection beat random sampling — both lift $R$ and $U$ and shrink variance across seeds. Without utility matching, the mean-difference vector absorbs foldability signal too, and UCCS collapses to a decoding-penalty-like trade-off.
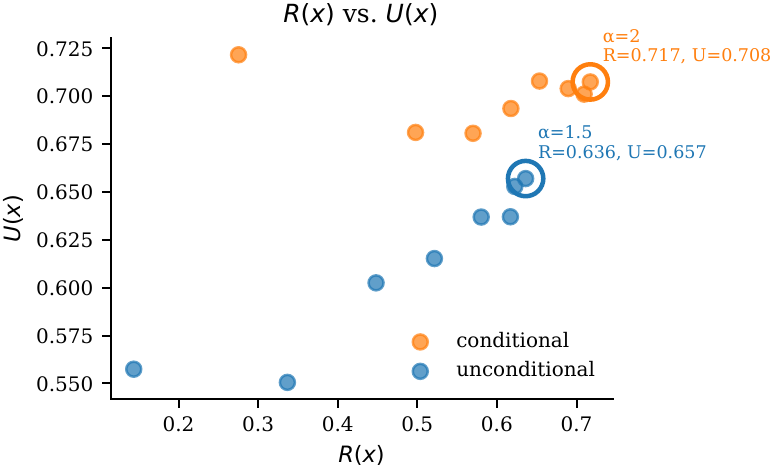
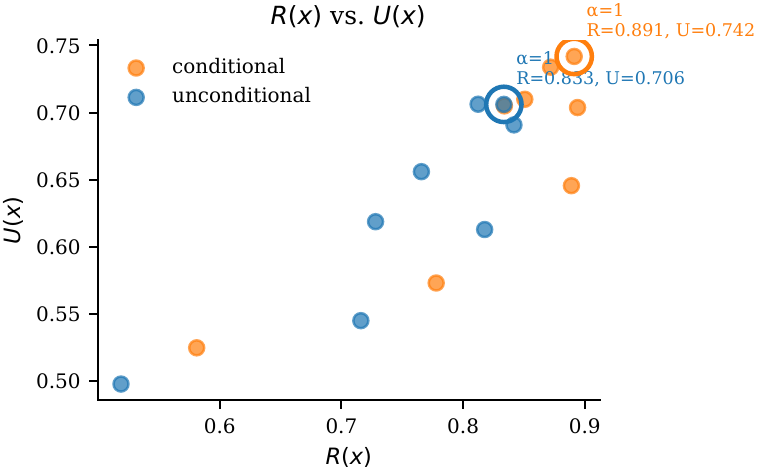
$\alpha$ is clearly unimodal in $[0.5, 4]$. Default $\alpha = 1$ gives the best $R$–$U$ harmonic mean. Conditional generation is noticeably more robust — a wider flat top.
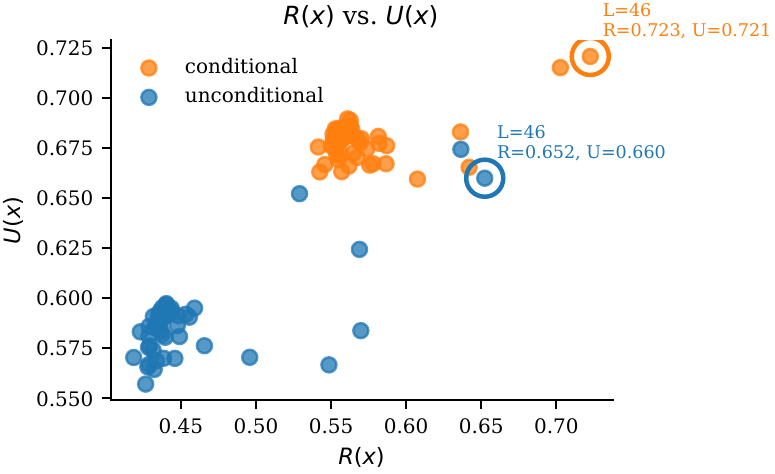
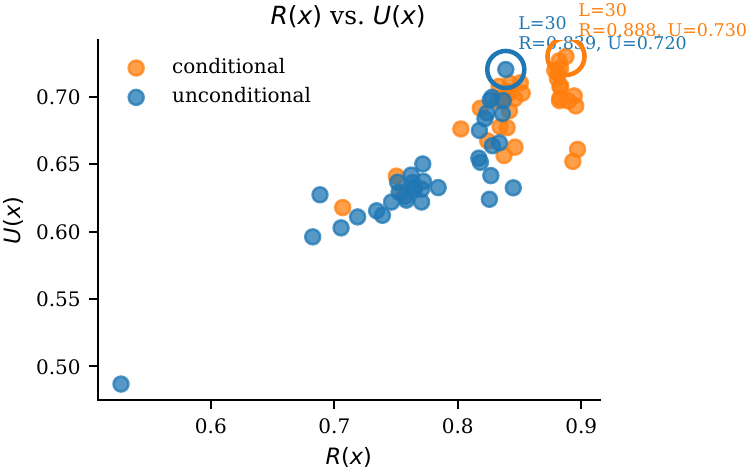
Injection in early layers is inert or harmful; late-layer injection (ESM-3 ≈ L46/48; ProtGPT2 ≈ L30/36) is monotonic-improving up to the penultimate layer — consistent with repetition features concentrating late in depth.
The appendix extends the study with (i) two additional protein language models spanning a new generation paradigm, and (ii) an initial mechanistic analysis of where "repetition" lives inside PLM activations.
Same baselines as ProtGPT2 (temperature, top-$p$, no-repeat-$n$-gram, repetition penalty). Across CATH / UniRef50 / SCOP, decoding heuristics barely move $R$ in the unconditional setting, while UCCS delivers consistent gains and is the only method satisfying the utility constraint across every condition. The latent repetition direction generalises to ProGen2's distinct architecture and training corpus.
A completely different generation mechanism. We sweep diffusion-specific knobs (sampling strategy, resample ratio, internal-resample on/off) — they trade $R$ and $U$ in unstable ways. UCCS still wins: $R = 0.863\text{–}0.879$ (unconditional) and $0.881\text{–}0.894$ (conditional), with $U$ improved over the original model. The method transfers across AR, MLM, and diffusion PLMs.
Pearson correlation between each neuron's activation and the repetition score, across all layers. Distributions are centered near zero with no isolated high-correlation outliers — repetition is not driven by a small set of specialised units.
Takeaway. Repetition is a distributed representational pattern → aligns with a direction/subspace in activation space, not individual neurons. This is exactly the object UCCS isolates via the mean-difference vector.
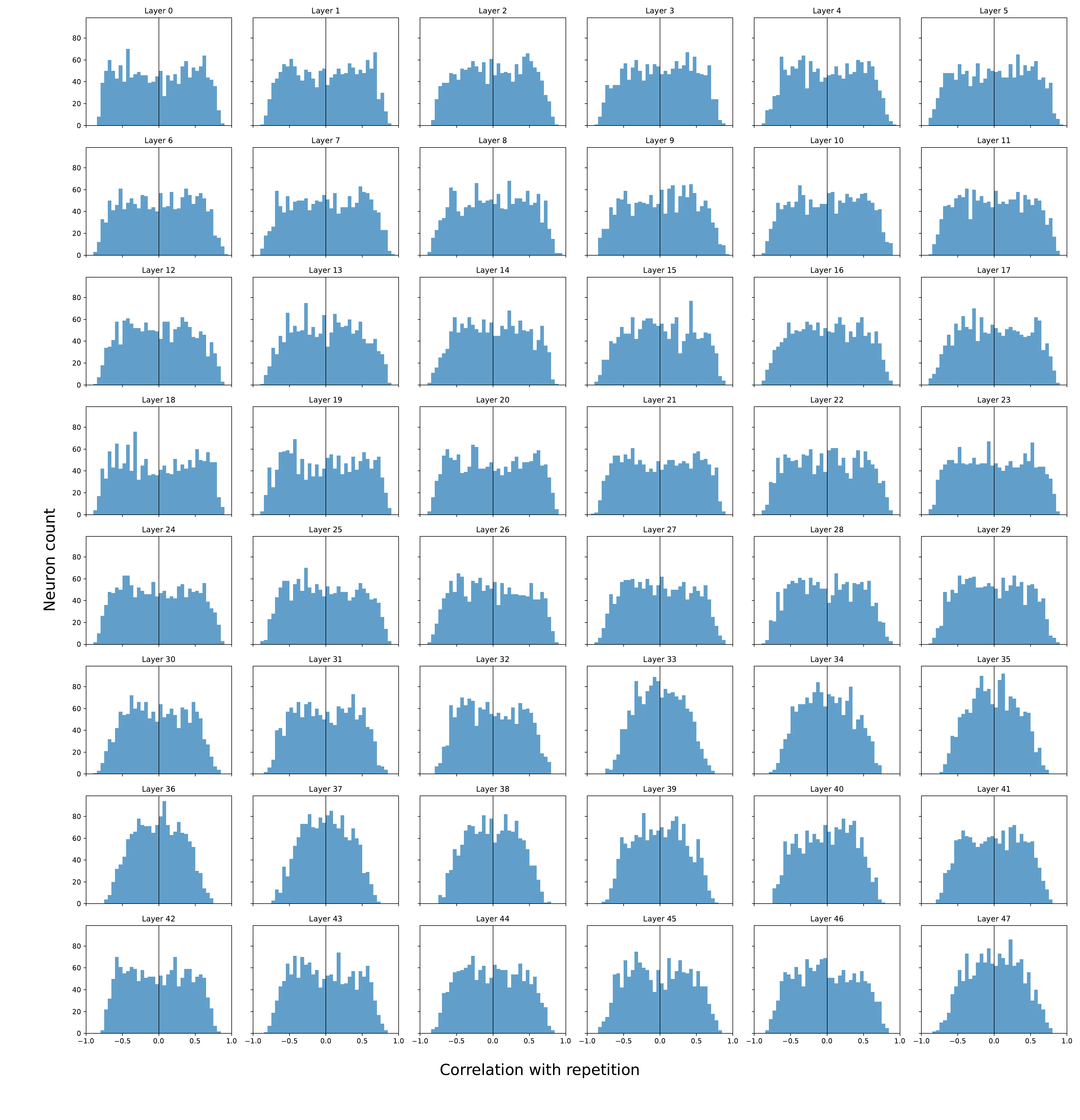
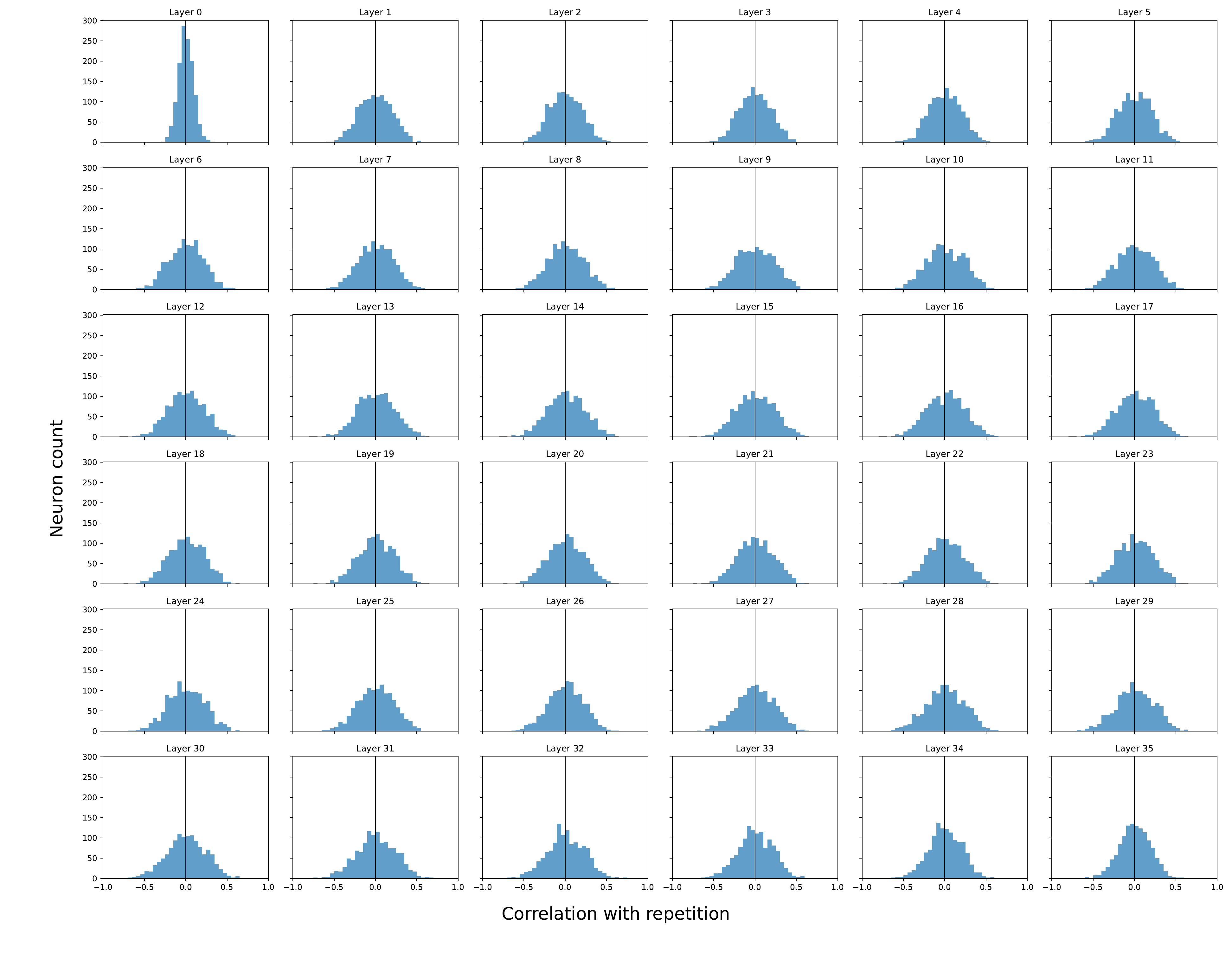
ESM-3's broader, more polarised distribution matches its empirically more severe repetition: architecture modulates the strength of the repetition subspace.
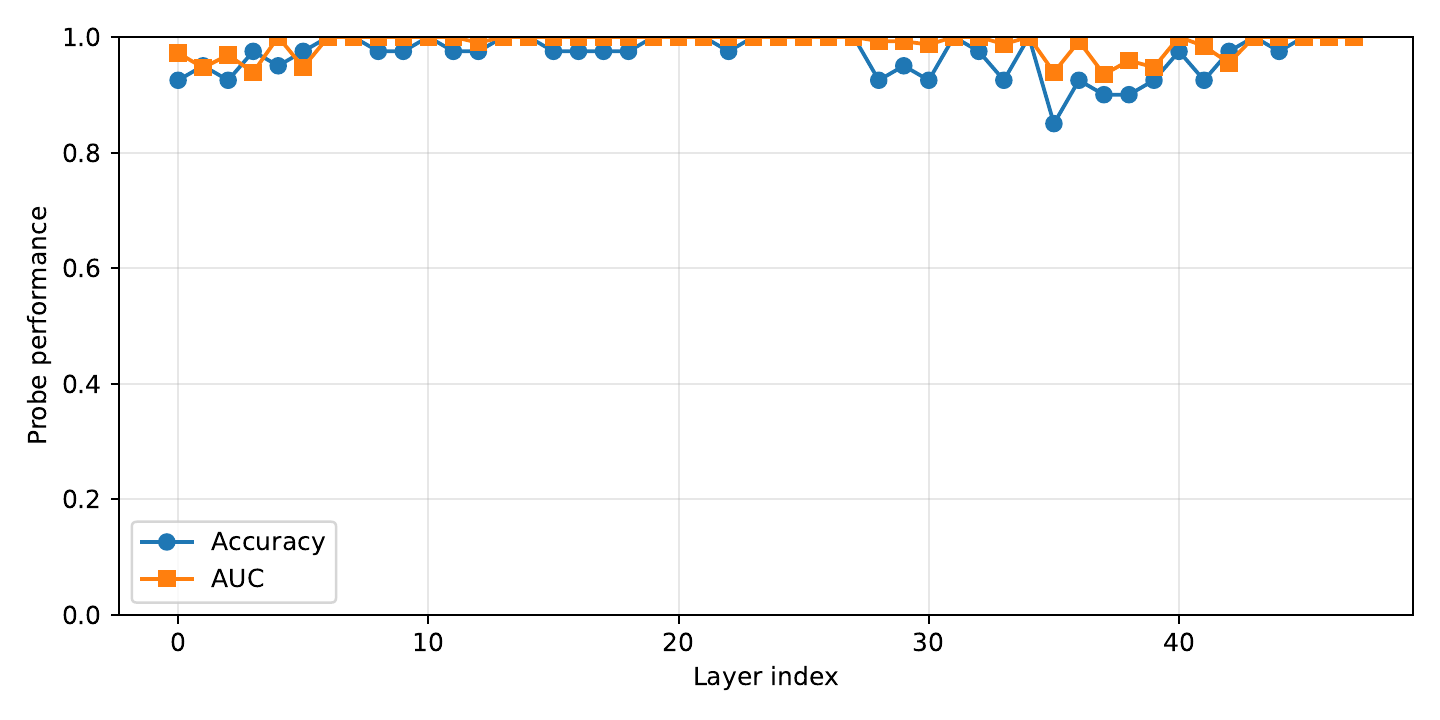
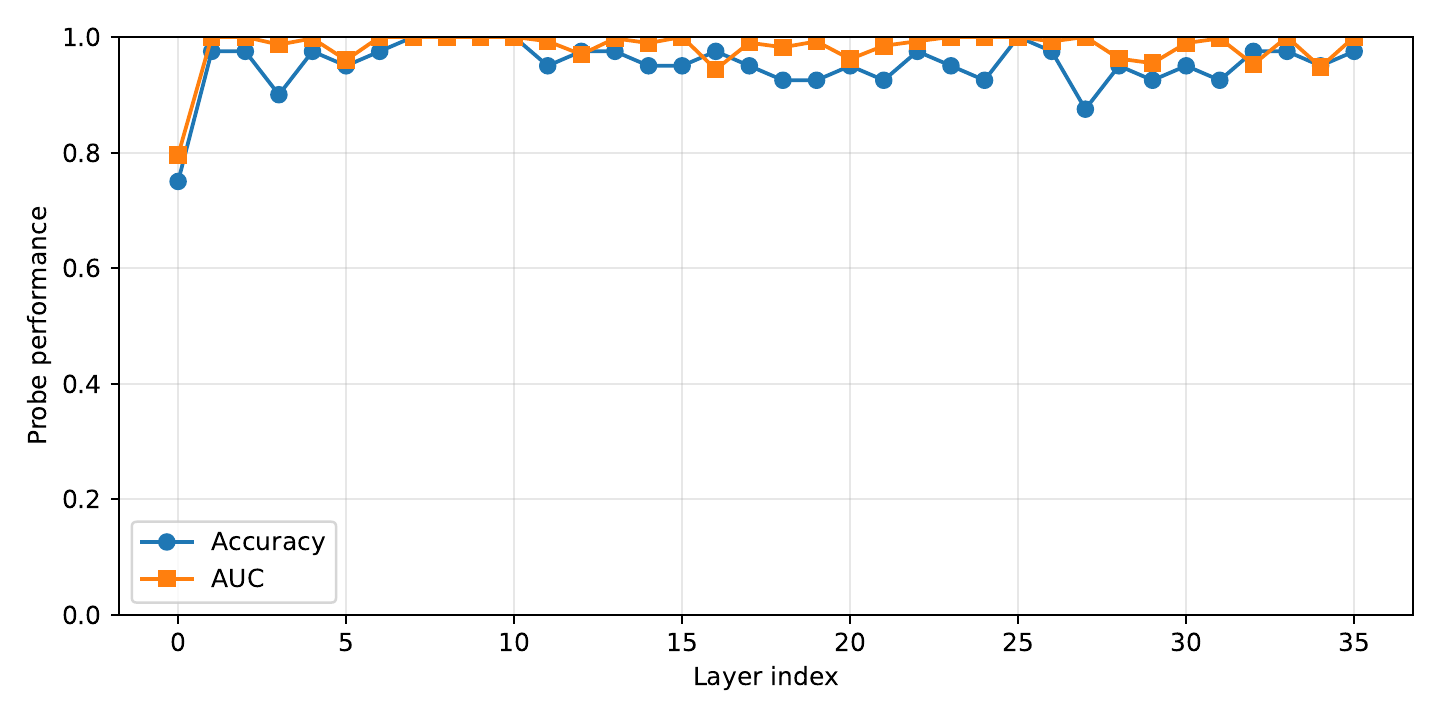
Linear probes trained to predict the repetition score from hidden activations at each layer. Probe performance grows sharply in later layers — the model's late-layer geometry encodes repetition most explicitly.
Takeaway. Same layers that probes find most informative are the layers where UCCS injection works best (ESM-3 $L \approx 46$, ProtGPT2 $L \approx 30$). The ablation in §Ablations is not a coincidence — it's consistent with the representational geometry.
Full tables for ProGen2 / DPLM and detailed mechanism figures are in the paper appendix.
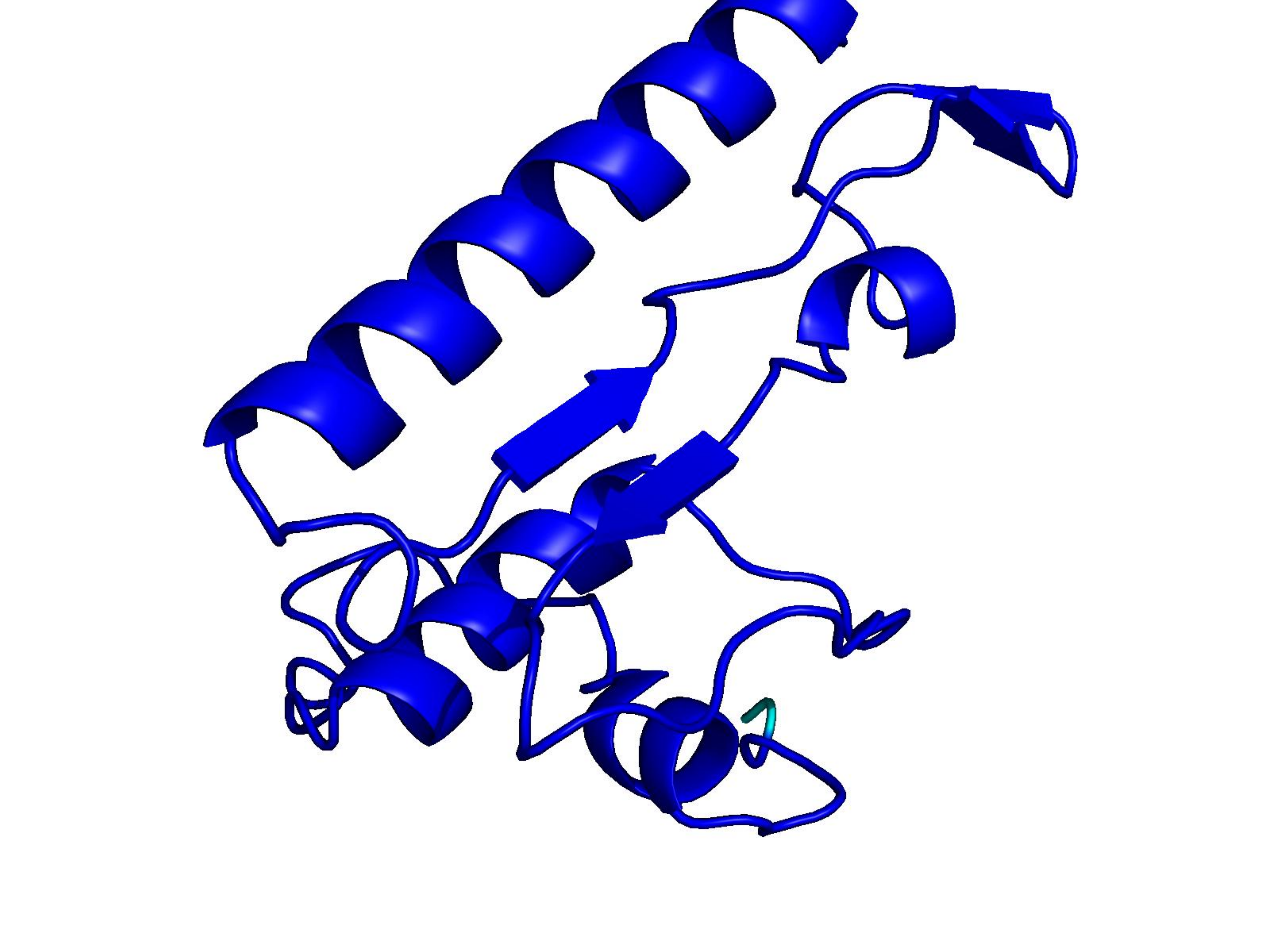
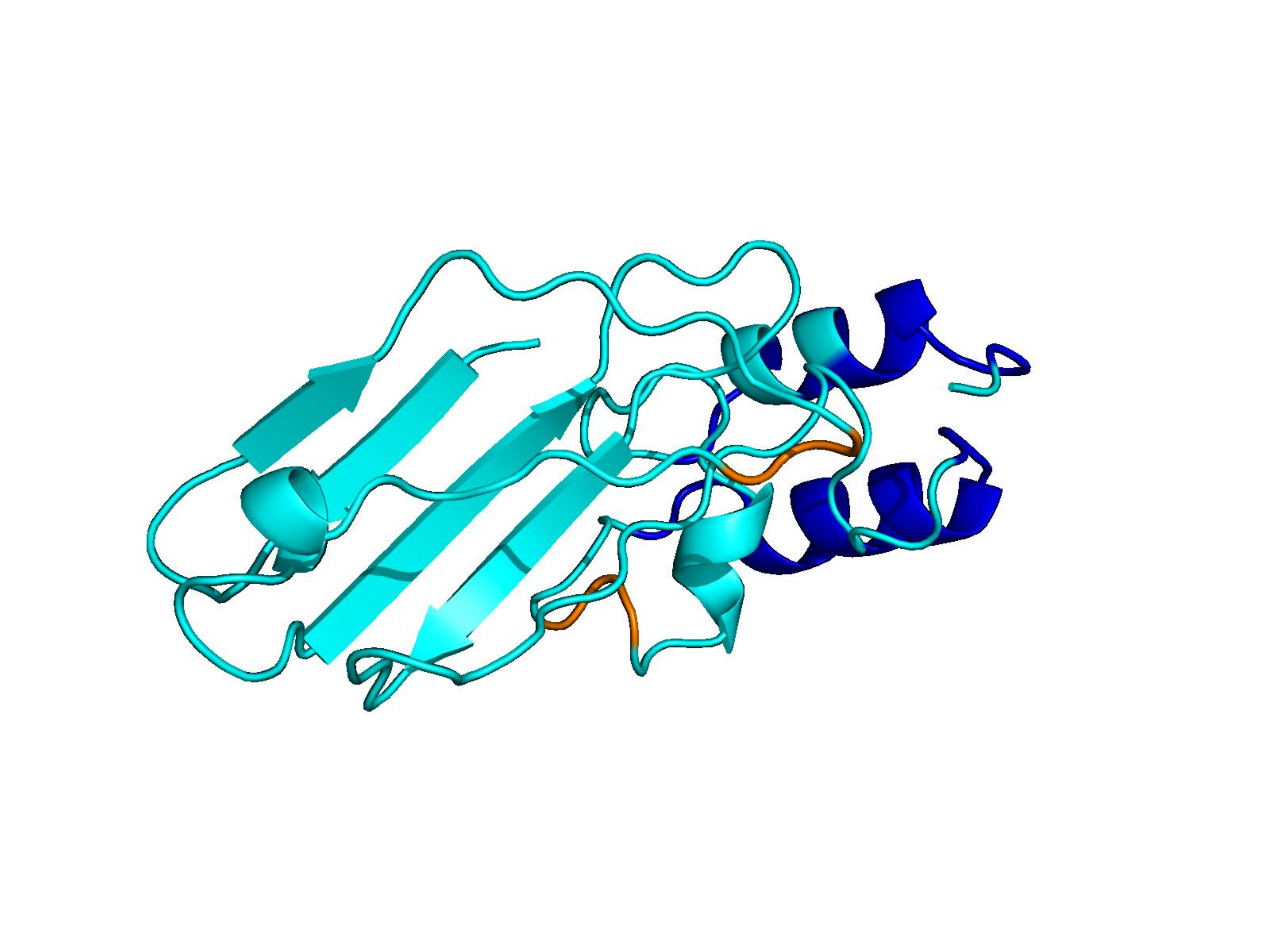
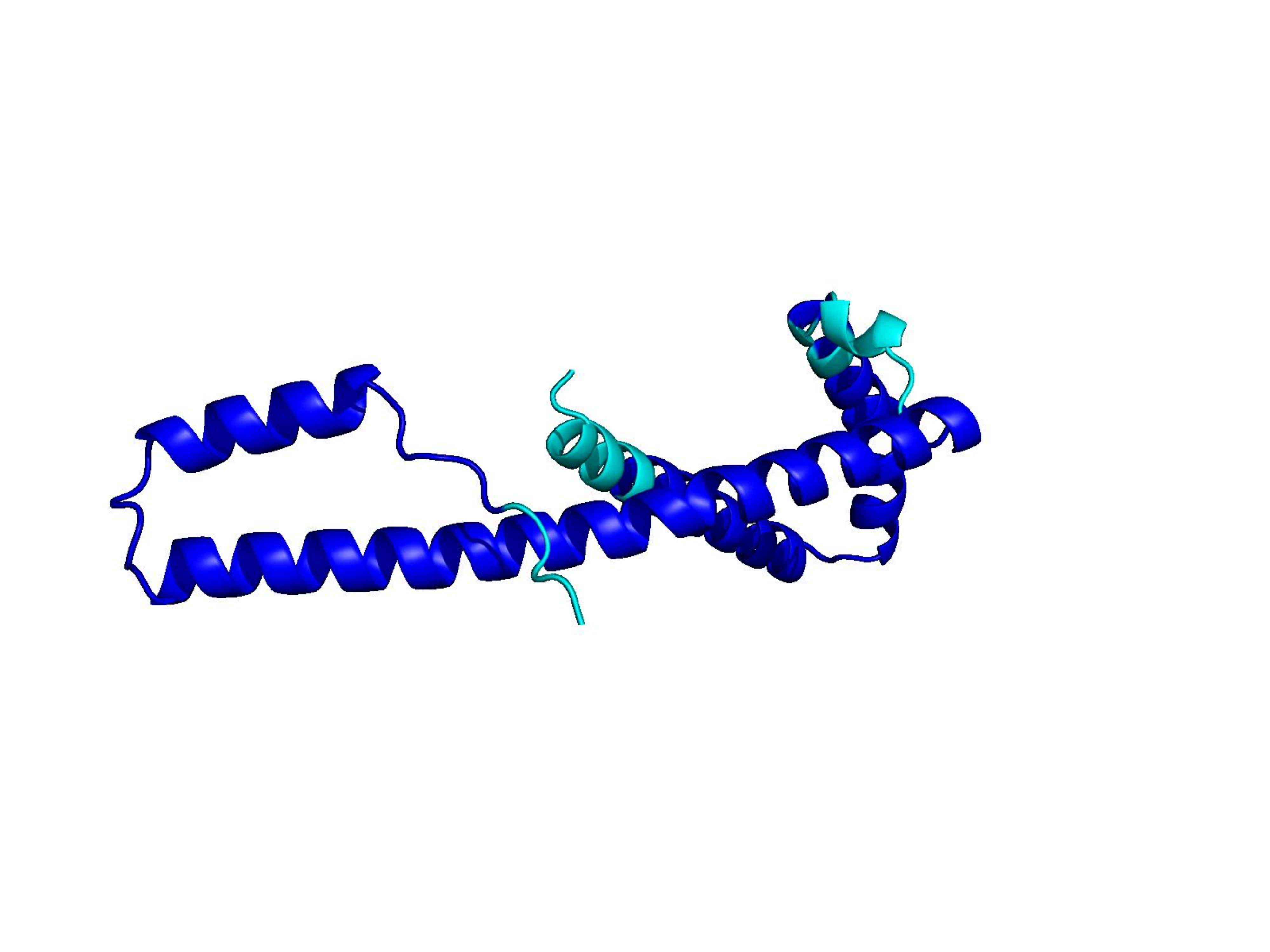
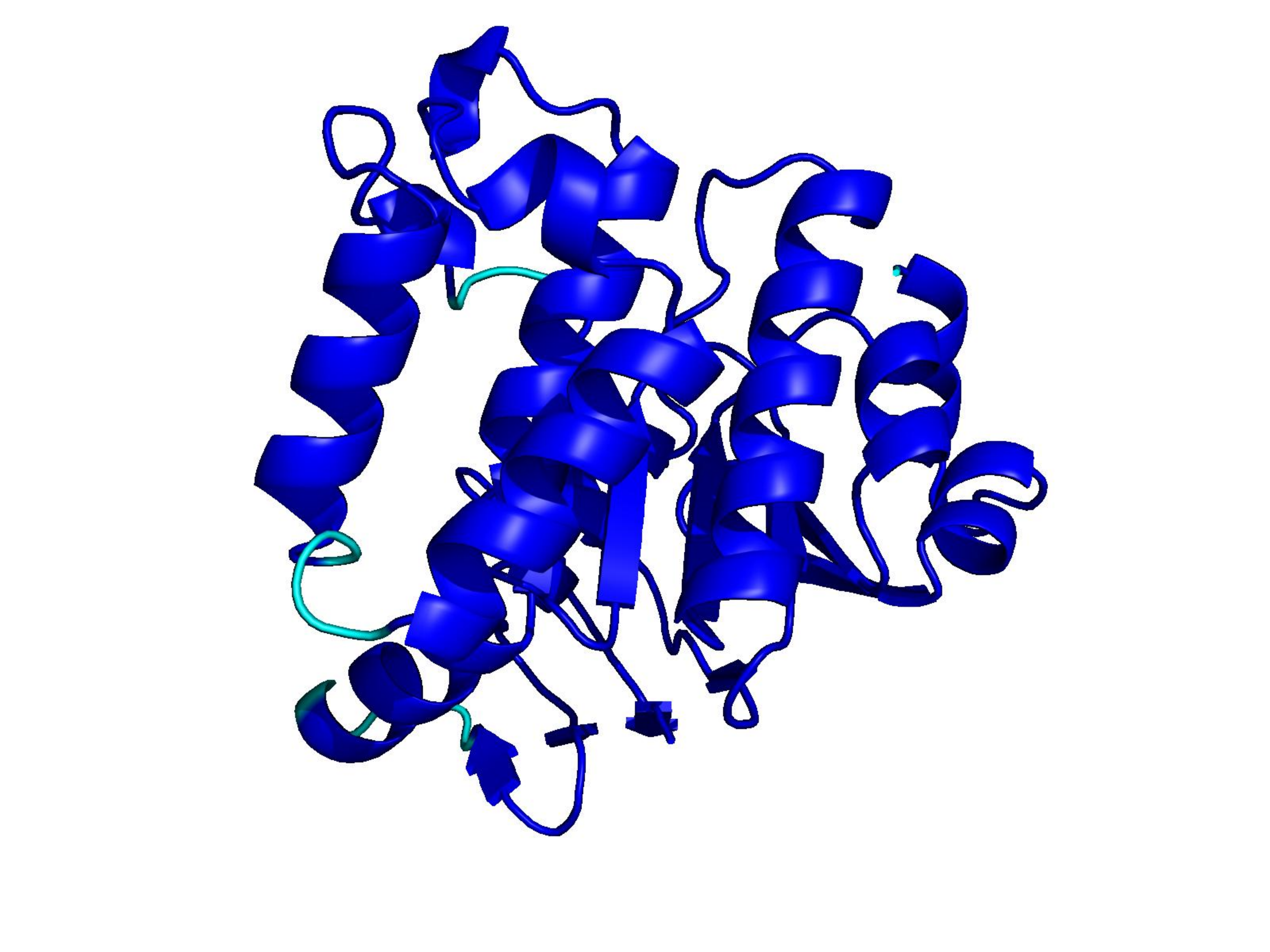
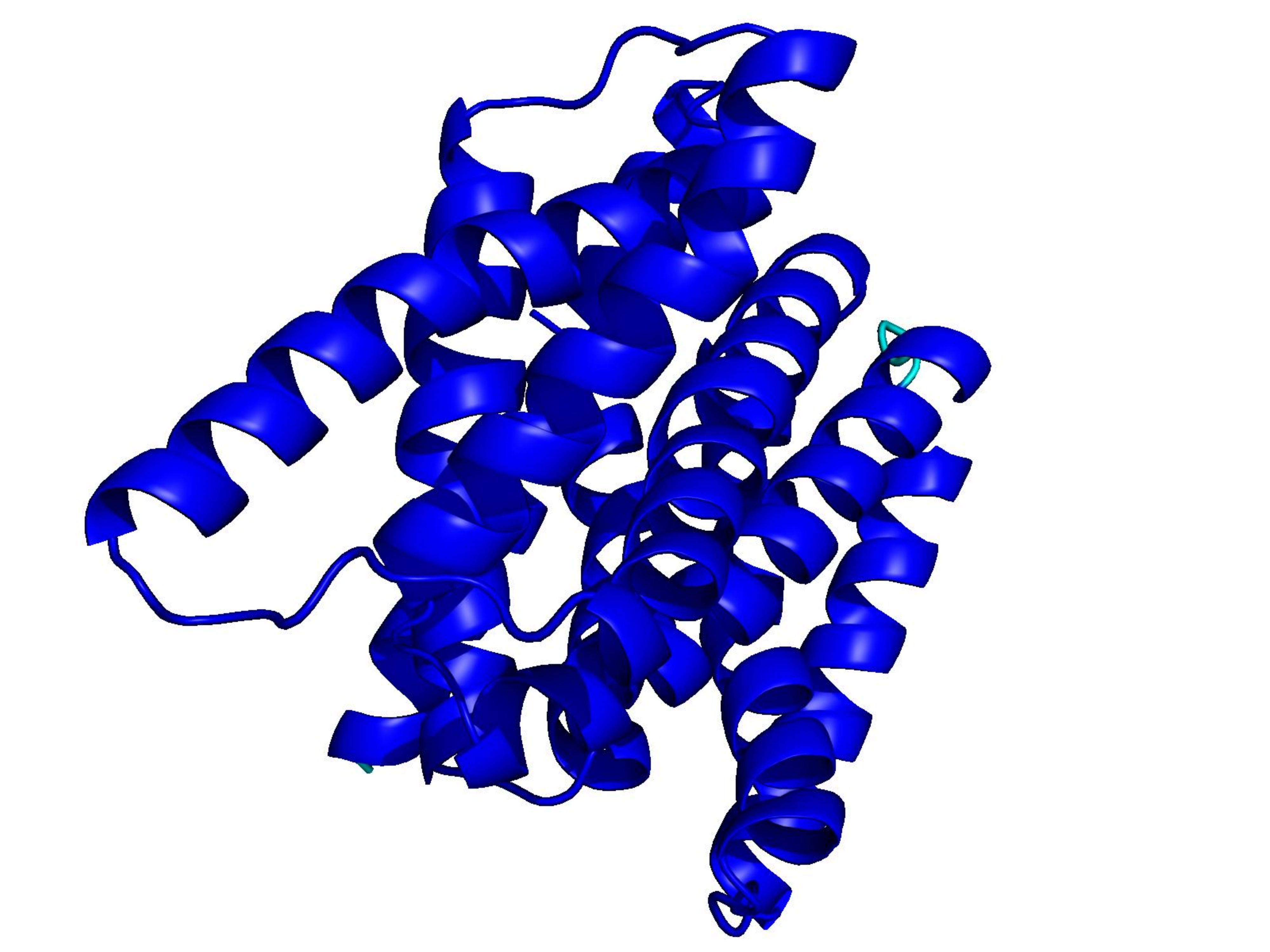
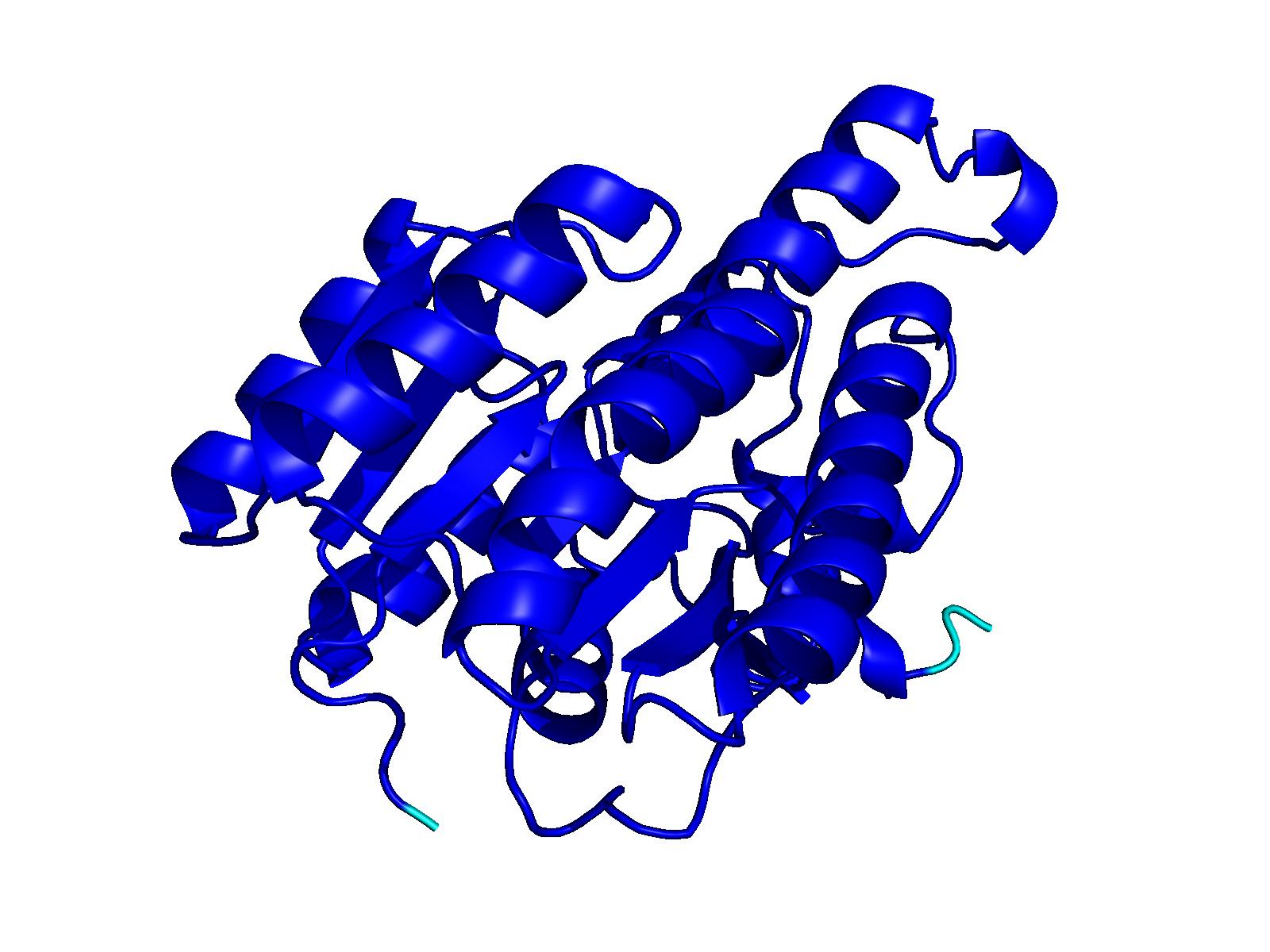
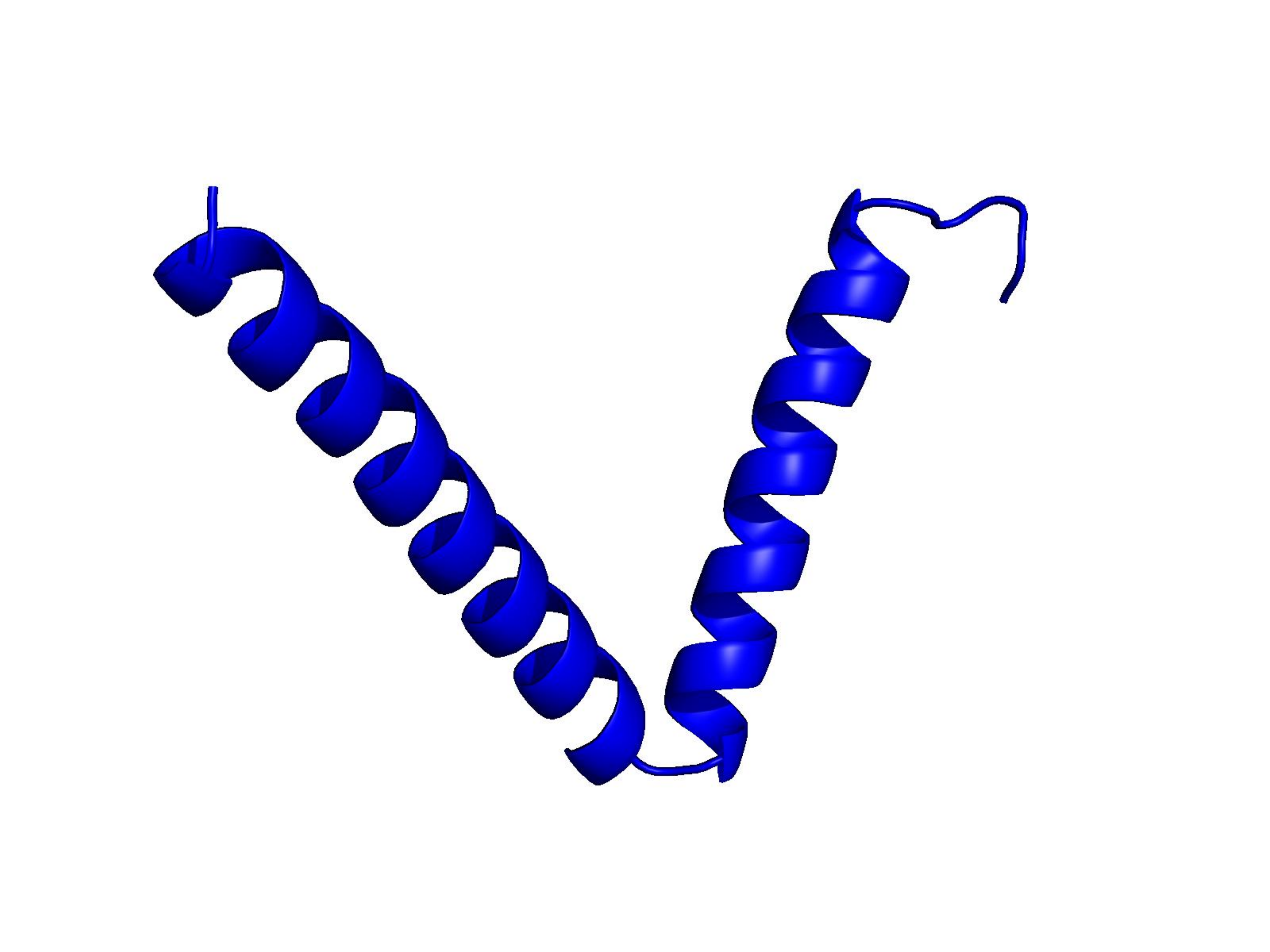
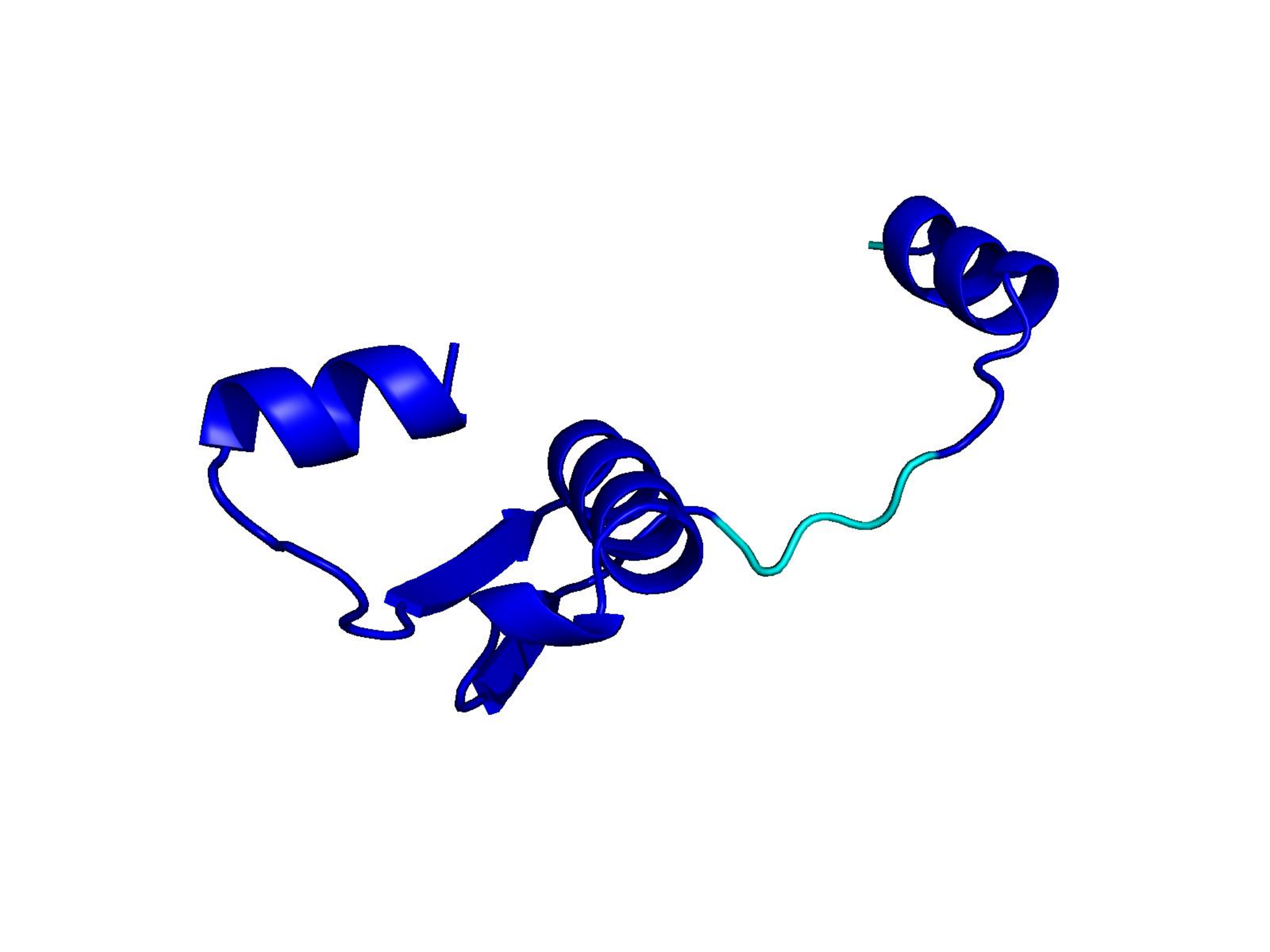
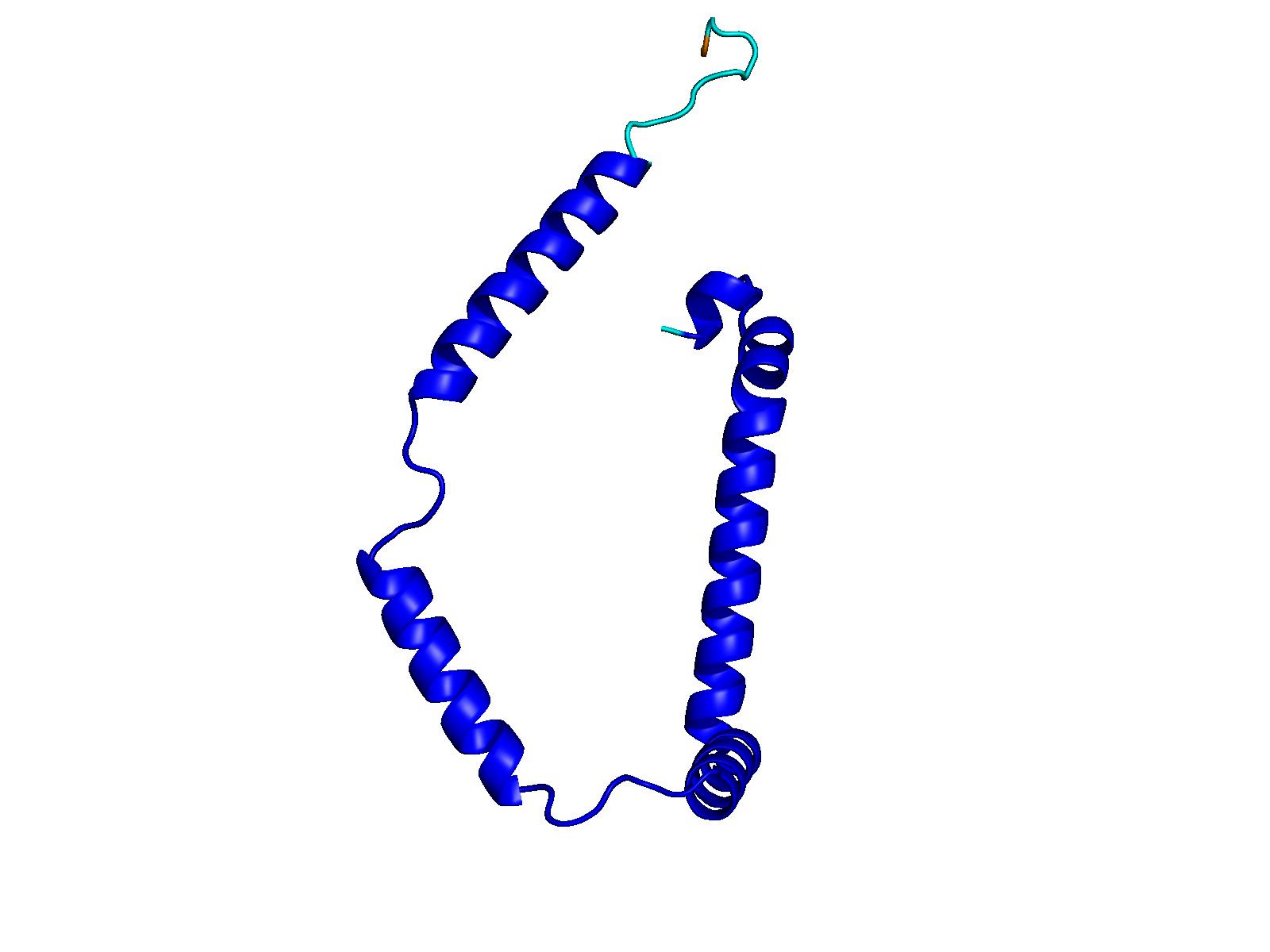
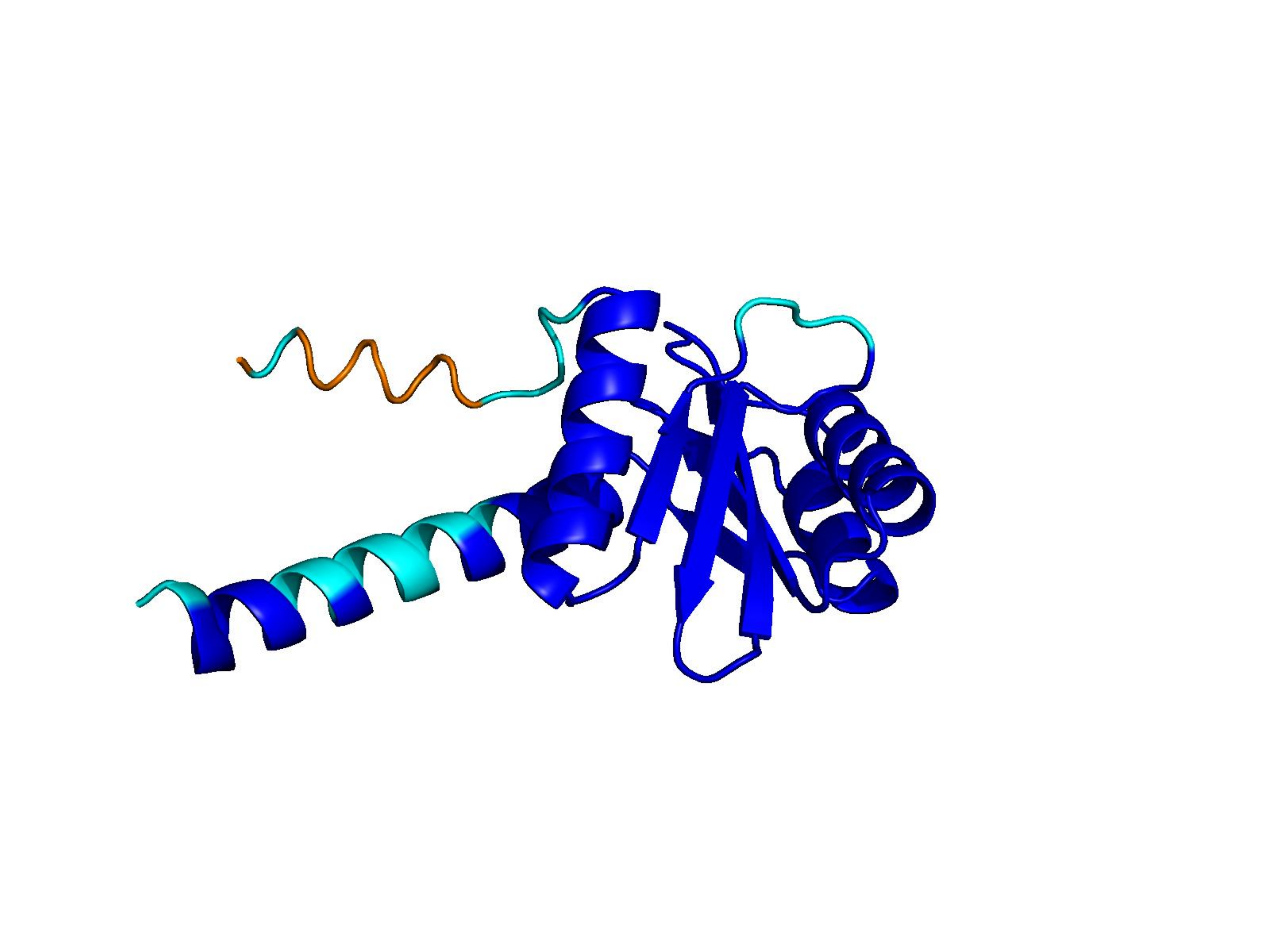
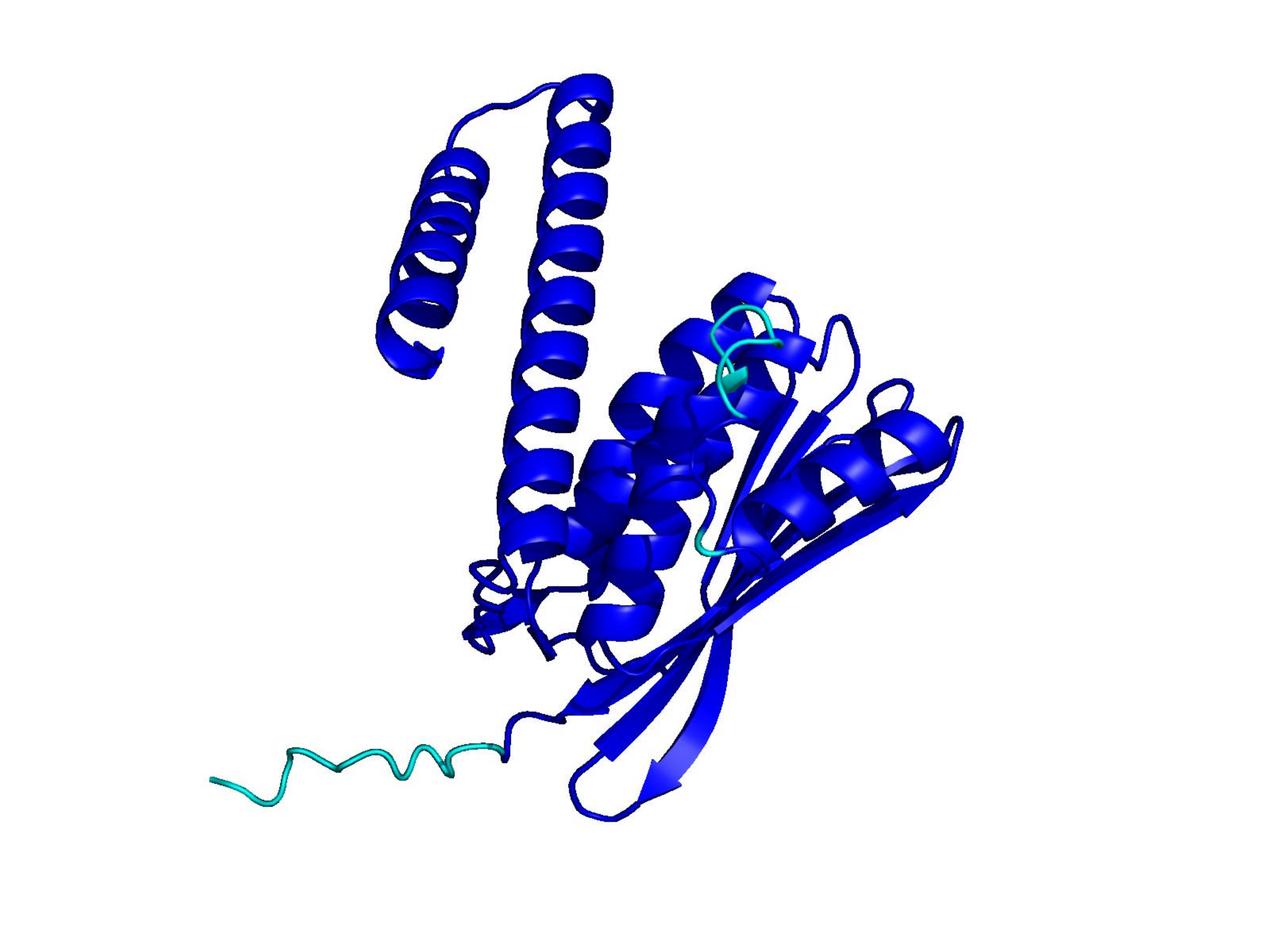
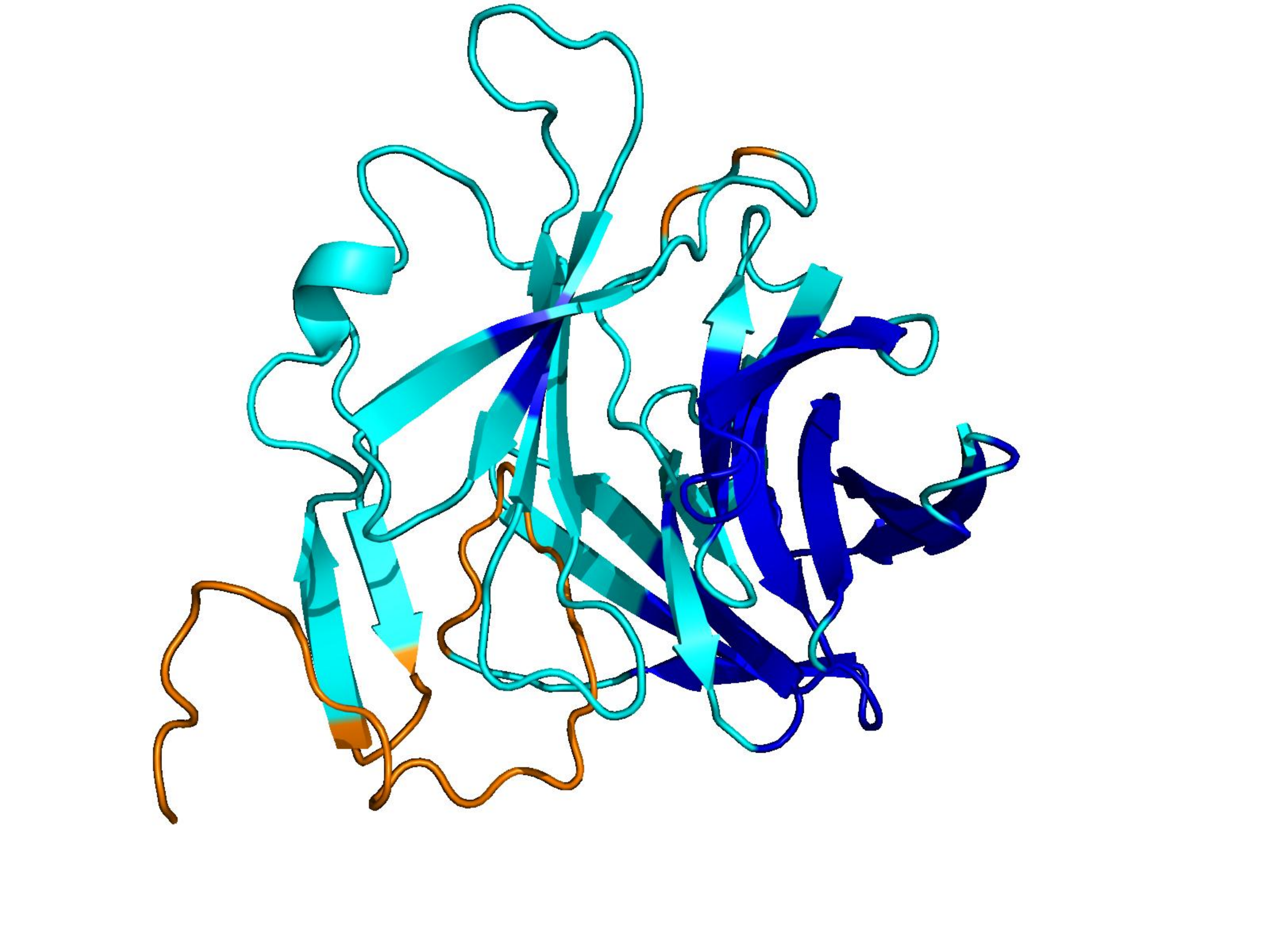
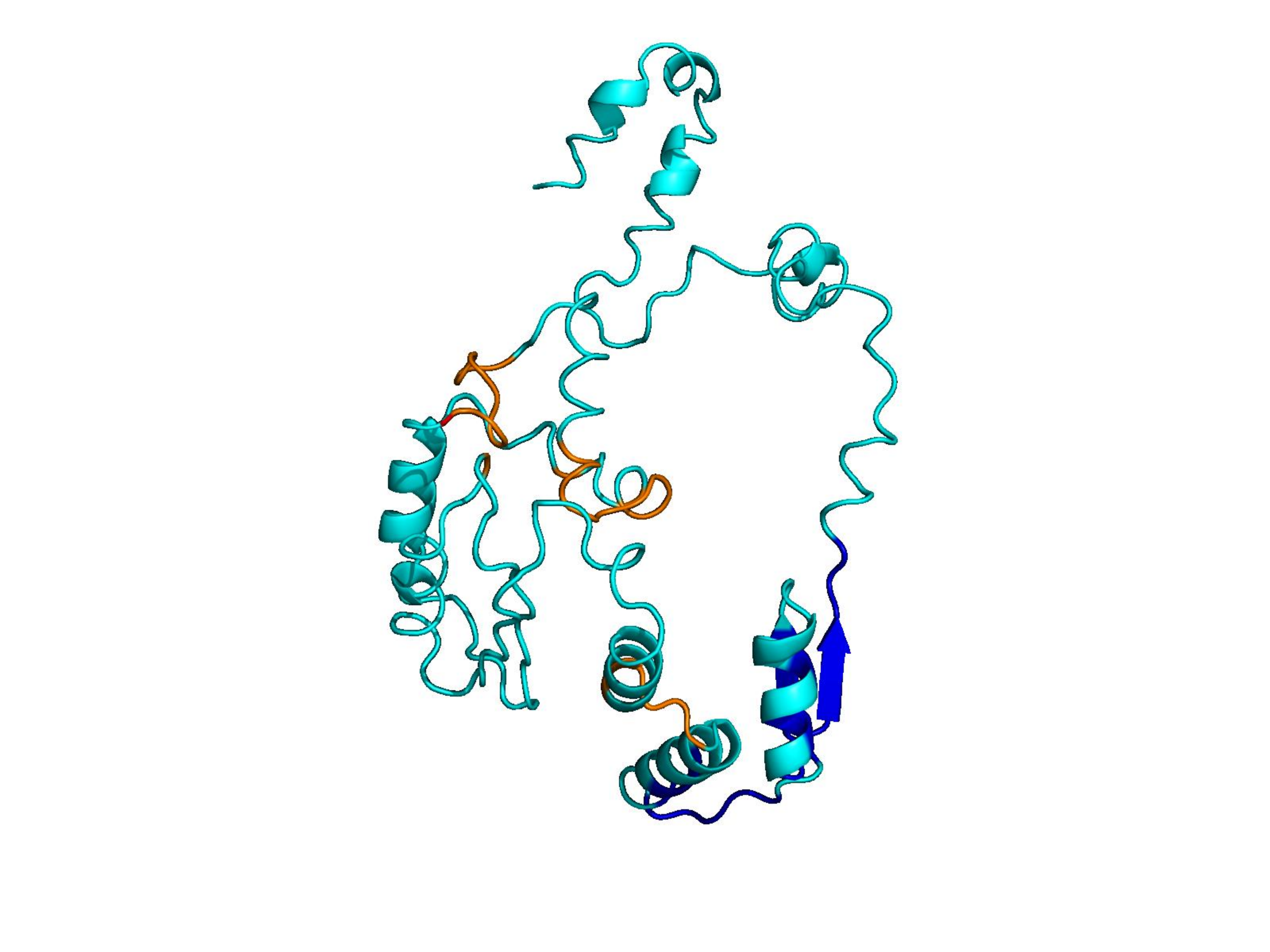
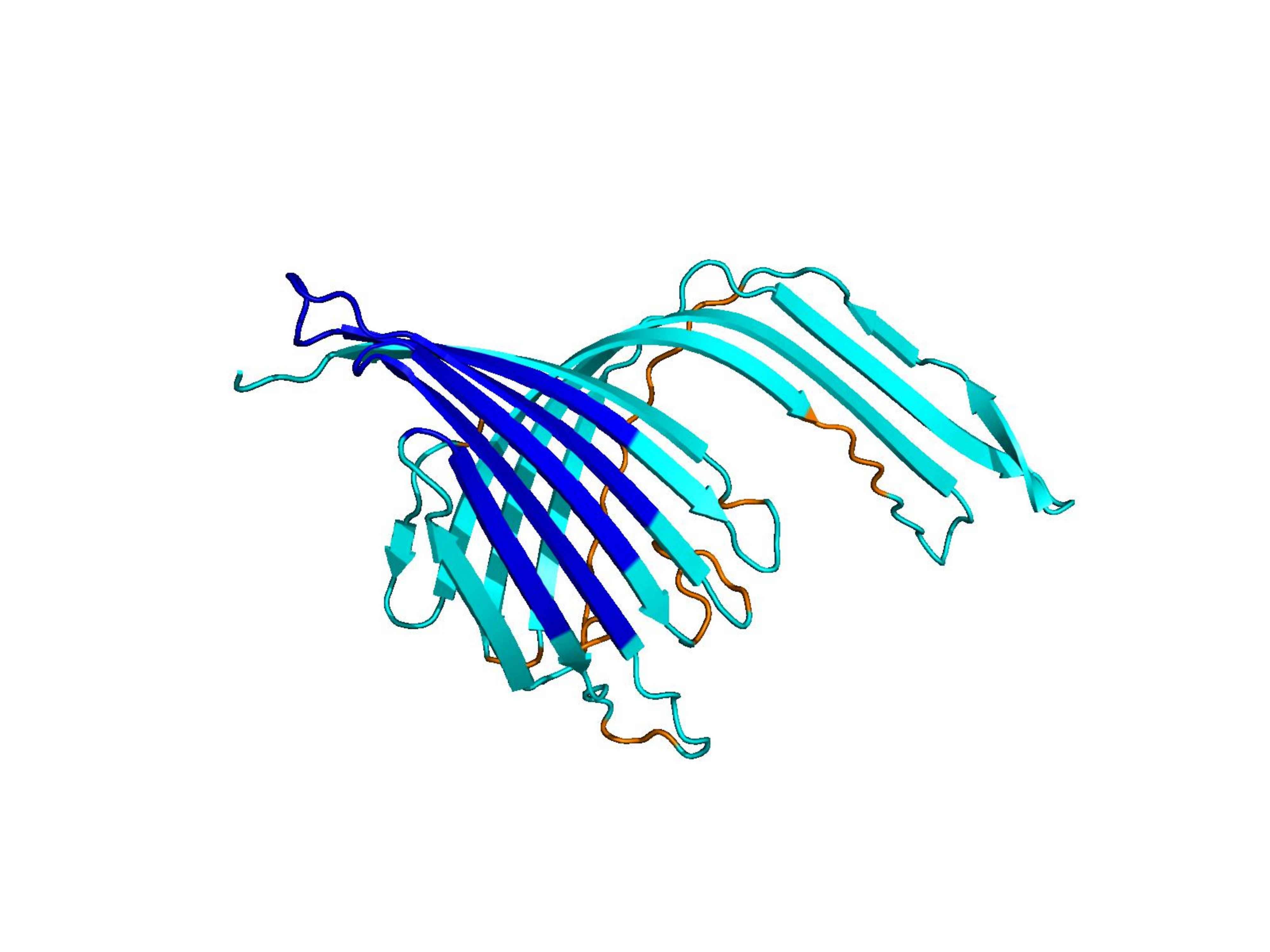
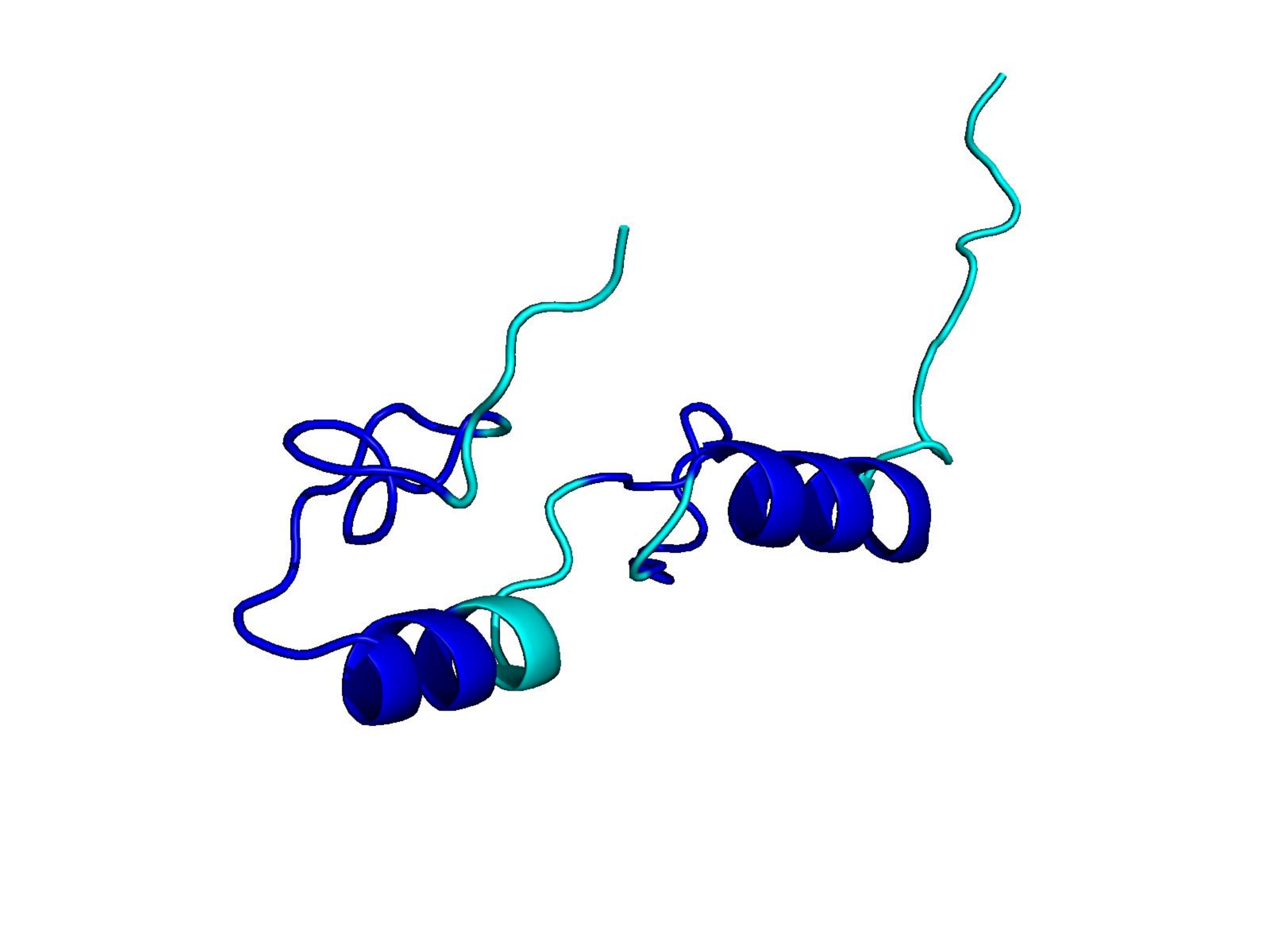
Unconditional generations from ESM-3 and ProtGPT2 after UCCS injection. Color = per-residue pLDDT (blue ≥ 90, cyan 70–90, orange/red < 70). Most cases are dominantly blue — the outputs actually fold. Click any image to enlarge.


@misc{zhang2026controllingrepetitionproteinlanguage,
title={Controlling Repetition in Protein Language Models},
author={Jiahao Zhang and Zeqing Zhang and Di Wang and Lijie Hu},
year={2026},
eprint={2602.00782},
archivePrefix={arXiv},
primaryClass={q-bio.BM},
url={https://arxiv.org/abs/2602.00782},
}